OJ题
1.IO型:自己写头文件,main函数等等
测试用例:我们要去scanf获取
结果:用printf输出
2.接口型(实现已知函数):不需要写头文件,主函数,提交了以后,会跟oj服务器上他准备好的代码合并
测试用例:通过参数传过来
结果:一般通过返回值拿的,也有可能是输出性参数
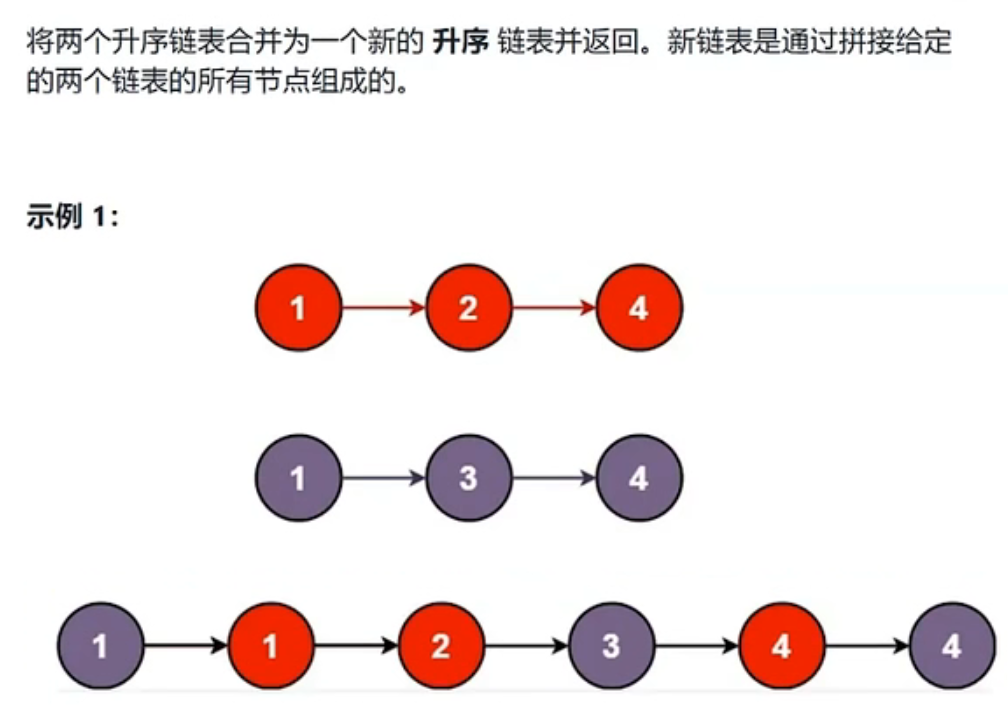
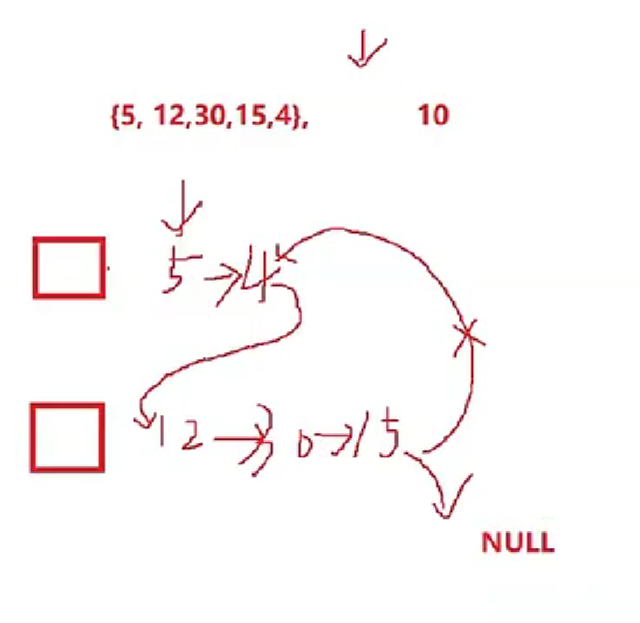
一个整形数组nums里除两个数字以外,其它数字都出现了2次,请写程序找出这两个只出现一次的数据
1
2
3
4
5
6
7
8
9
|
int* singleNumbers(int8 nums,int numsSize,int * returnSize)
{
*returnSize=2;
int* arr=(int*)malloc(sizeof(int)*2);
return arr;
}
|
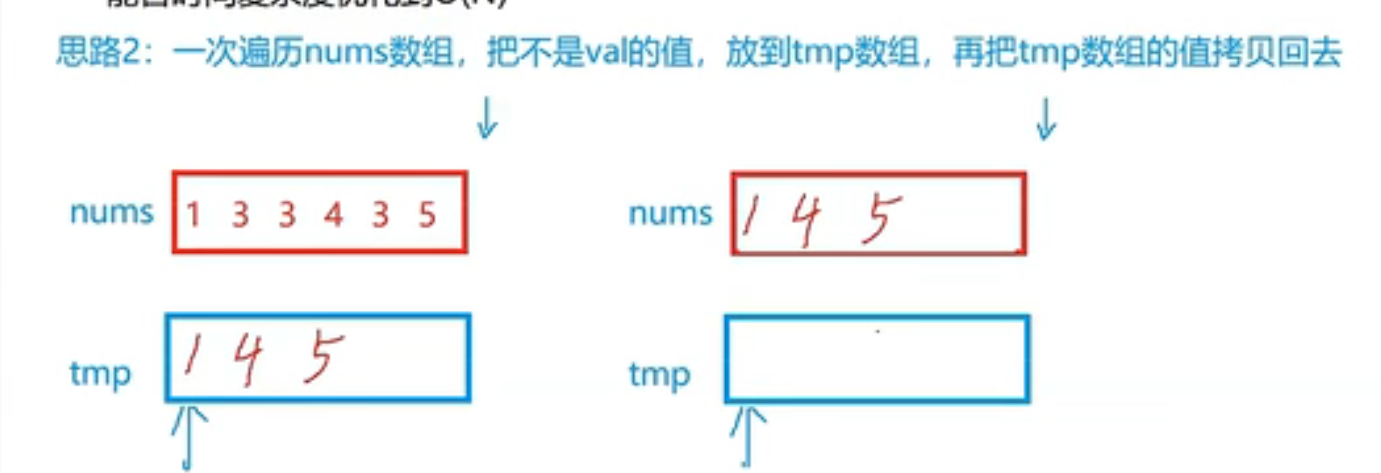
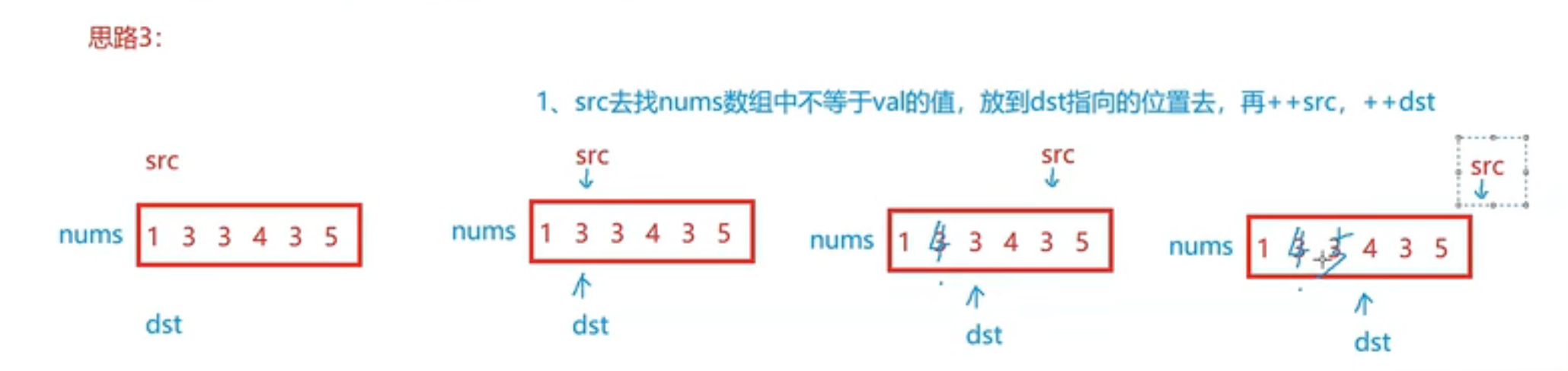
给你一个数组nums和一个值val,你需要原地溢出所有数值相等于val的元素,并返回移除后数组的新长度

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| int removeElement(int* nums,int numSize,int val)
{
int src=0,dst=0;
while(src<numSize)
{
if(nums[src]!=val)
{
nums[dst]=nums[src];
src++;
dst++;
}
else
{
src++;
}
}
return dst;
}
|
去重,删除有序数组中的重复数字(双指针的变形)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
int removeDuplicates(int* nums,int numsSize)
{
if(numsSize==0)
return 0;
int i=0,j=1;
int dst=0;
while(j<numsSize)
{
if(nums[i]==nums[j])
{
++j;
}
else
{
nums[dst]=nums[i];
++dst;
i=j;
j++
}
}
nums[dst]=nums[i];
++dst;
return dst;
}
|
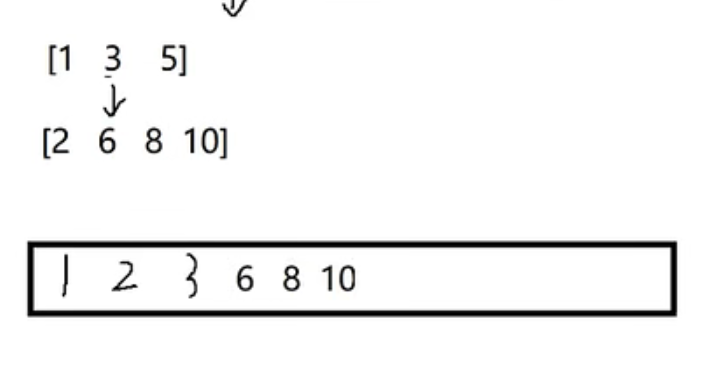
合并两个有序数组(归并排序)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
void merge(int* nums1,int nums1Size,int m,int* nums2,int nums2Size,int n)
{
int end1=m-1,end2=n-1;
int end=m+n-1;
while(end1>=0 && end2>=0)
{
if(nums[end1]>nums2[end2])
{
nums1[end]=nums1[end1];
--end2;
--end1;
}
else
{
nums1[end]=nums2[end2];
--end2;
--end1;
}
}
while(end2>=0)
{
nums1[end]=nums[end2];
--end2;
--end;
}
}
|
图2
此题是从后往前放数据从大到小开始放;而归并排序是从小到大比较从前往后放,并且归并排序是生成一个新数组存放排过序的元素
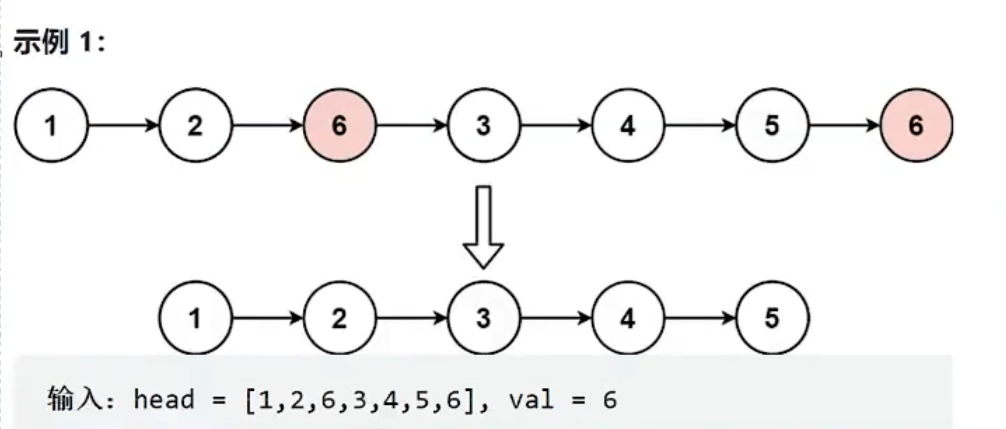
移除链表元素(给你一个链表的头节点head和一个整数val,请你删除链表中所有满足Node.val==val的节点,并返回新的头节点)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| struct ListNode* removeElement(struct ListNode* head,int val)
{
struct Listnode* prev=NULL,*cur=head;
while(cur)
{
if(cur->val==val)
{
if(cur==head)
{
head=cur->next;
free(cur);
cur=head;
}
else
{
prev->next=cur->next;
free(cur);
cur=prev->next;
}
}
else
{
prev=cur;
cur=cur->next;
}
}
return head;
}
|
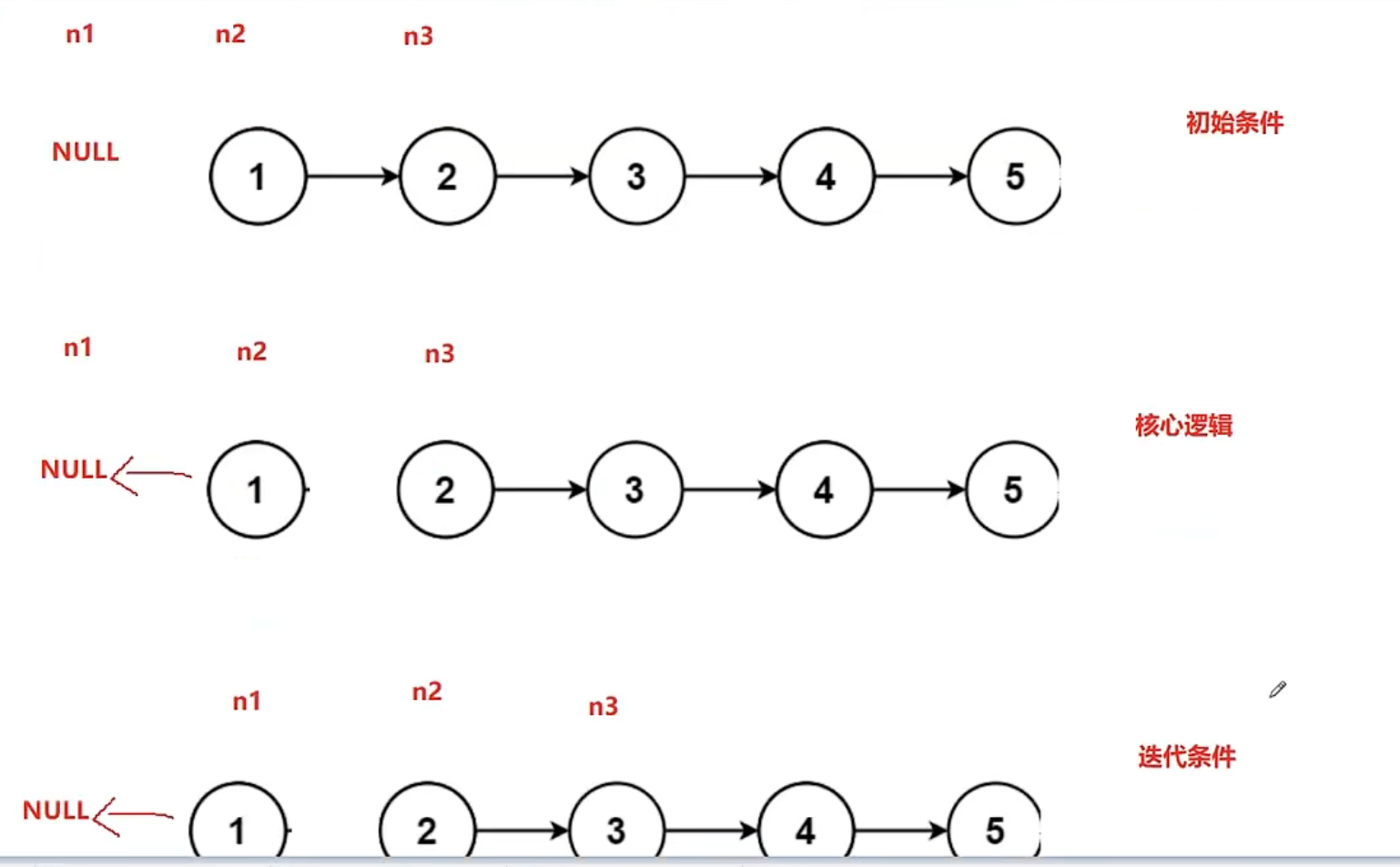
翻转链表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| struct ListNode* reverseList(struct ListNode* head)
{
if(head==NULL)
return NULL;
struct ListNode* n1,n2,n3;
n1=NULL;
n2=head;
n3=head->next;
while(n2)
{
n2->next=n1;
n1=n2;
n2=n3;
if(n3!=NULL)
n3=n3->next;
}
return n1;
}
|
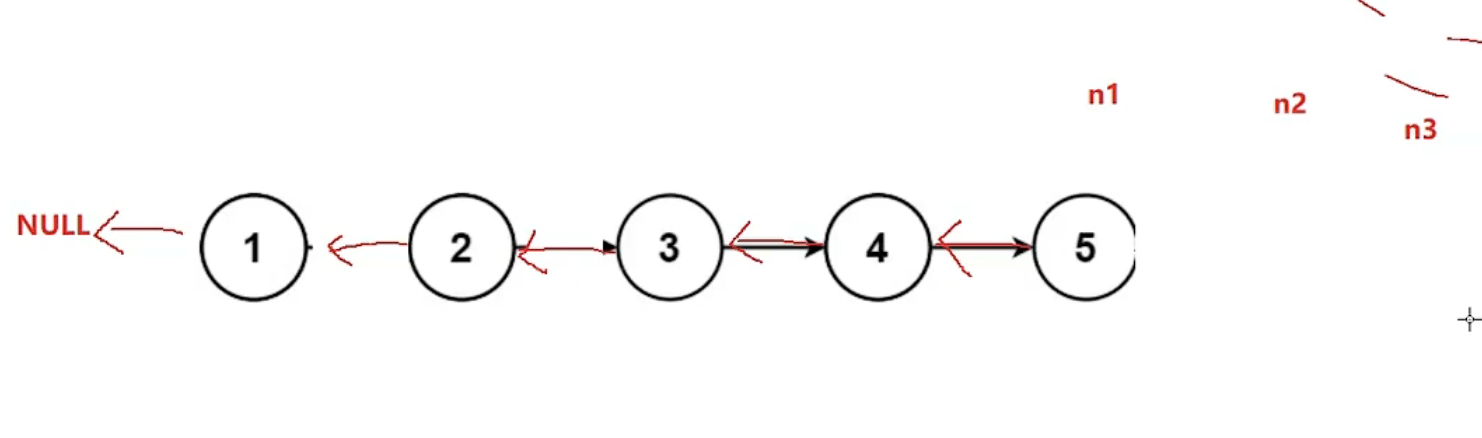
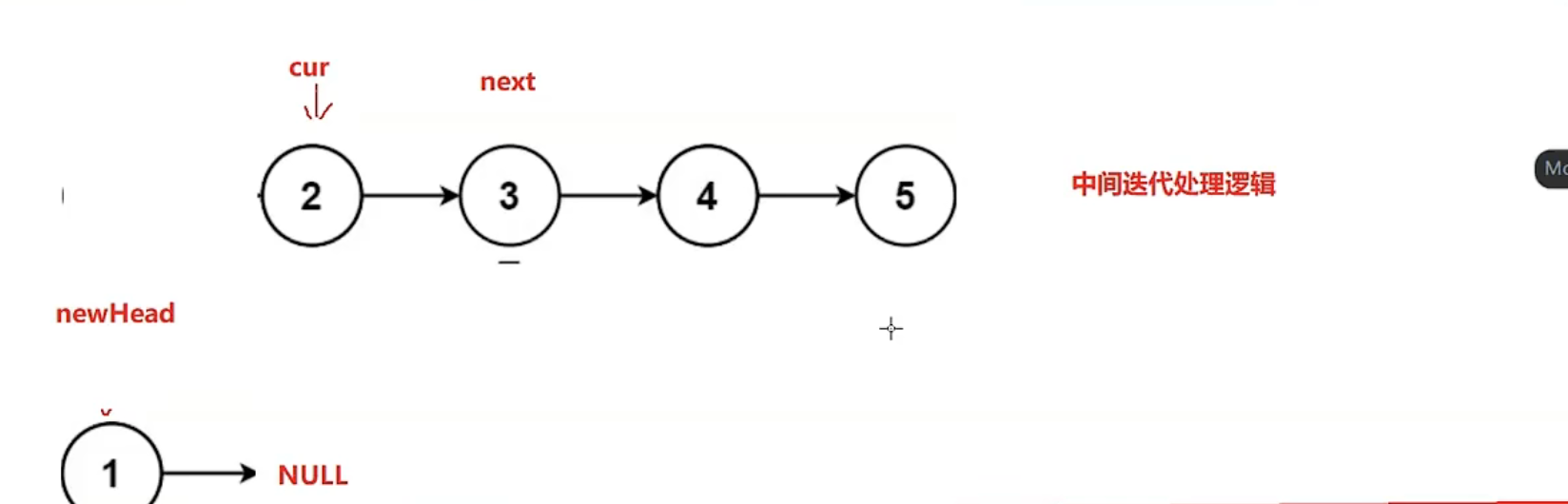
上图为基本翻转逻辑,下图为for循环结束条件图示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
struct ListNode* reverseList(struct ListNode* head)
{
struct ListNode*cur=head;
struct ListNode* newhead=NULL;
while(cur)
{
struct ListNode* next=cur->next;
cur->next=newhead;
newhead=cur;
cur=next;
}
return newhead;
}
|
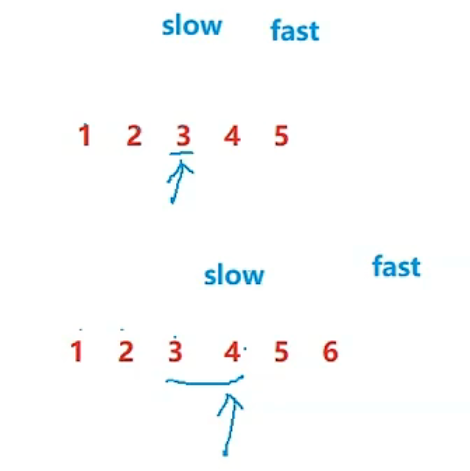
返回链表的中间节点(如果有两个中间节点则返回第二个中间节点) 要求:只能遍历链表一次
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
struct ListNode* middleNode(struct ListNode* head)
{
struct ListNode* slow,*fast;
slow=fast=head;
while(fast&&fast->next)
{
slowslow->next;
fast=fast->next->next;
}
return slow;
}
struct ListNode* FindKthToTail(struct ListNode* plistHead,int k)
{
struct ListNode* fast,*slow;
slow=fast=plistHead;
while(k--)
{
fast=fast->next;
if(fast==NULL)
{
retuen NULL;
}
}
while(fast)
{
slow=slow->next;
fast=fast->next;
}
return slow;
}
|
上图为变形前的示意图
合并两个有序列表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
struct ListNode* mergeTwoLists(struct ListNode* l1,struct ListNode* l2)
{
if(l1==NULL)
return l2;
if(l2==NULL)
return l1;
struct ListNode* head=NULL,*tail=NULL;
while(l1&&l2)
{
if(li->val<l2->val)
{
if(head==NULL)
{
head=tail=l1;
}
else
{
tail->next=l1;
tail=tail->next;
}
l1=l1->next;
}
else
{
if(head==NULL)
{
head=tail=l2;
}
else
{
tail->next=l2;
tail=tail->next;
}
l2=l2->next;
}
if(l1)
{
tail->next=l1;
}
if(l2)
{
tail->next=l2;
}
return head;
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| if(l1==NULL)
return l2;
if(l2==NULL)
return l1;
struct ListNode* head=NULL,*tail=NULL;
head=tail=(struct ListNode*)malloc(sizeof(struct ListNode));
while(l1&&l2)
{
if(li->val<l2->val)
{
tail->next=l1;
tail=tail->next;
l1=l1->next;
}
else
{
tail->next=l2;
tail=tail->next;
l2=l2->next;
}
}
if(l1)
{
tail->next=l1;
}
if(l2)
{
tail->next=l2;
}
struct ListNode*list=head->next;
free(head);
return list;
|
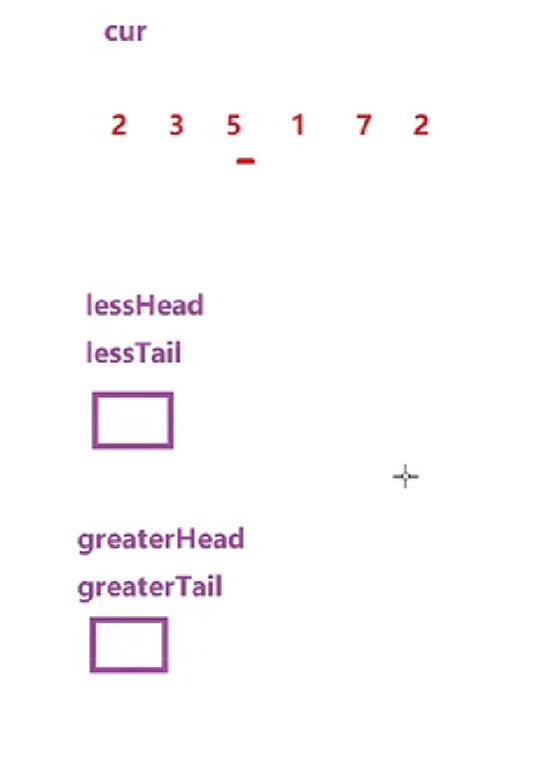
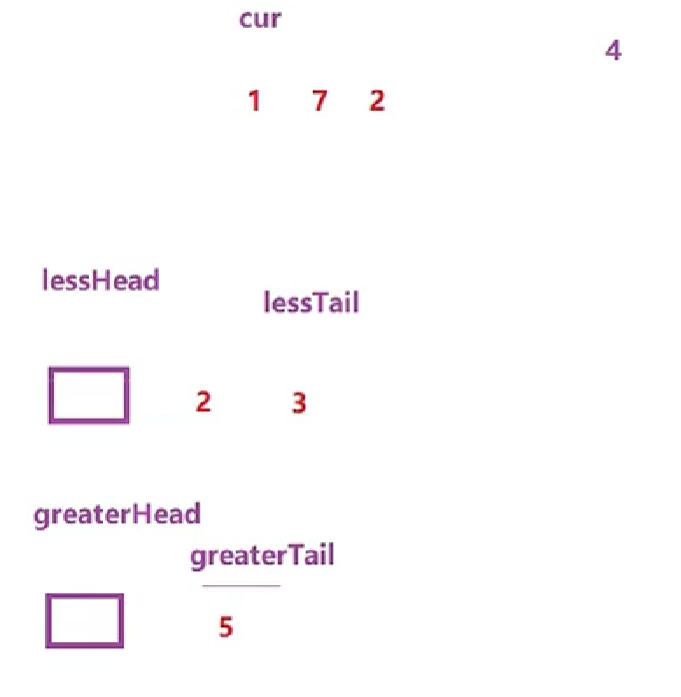
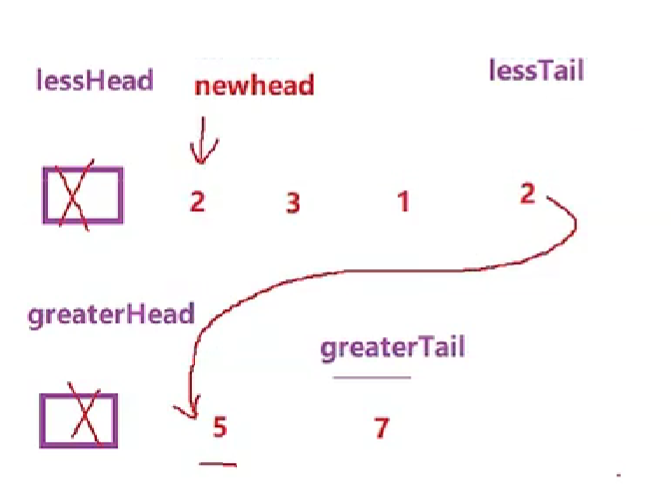
链表的分割(现在有一链表的头指针ListNode* pHead,给一定值x,编写一段代码将所有小于x的节点排在其余节点之前,且不能改变原来的数据顺序,返回重新排列后的链表的头指针)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
ListNode* partition(ListNode* pHead,int x)
{
struct ListNode* lessHead,*lessTail,*greaterHead,*greaterTail;
lessHead=lessTail=(struct ListNode*)malloc(sizeof(strcut ListNode*));
lessTail->next=NULL;
greaterHead=lessTail=(struct ListNode*)malloc(sizeof(strcut ListNode*));
greaterTail->next=NULL;
struct ListNode* cur=pHead;
while(cur)
{
if(cur->val<x)
{
lessTail->next=cur;
lessTail=cur;
}
else
{
greaterTail->next=cur;
greaterTail=cur;
}
cur=cur->next;
}
lessTail->next=greaterHead->next;
greater->next=NULL;
struct ListNode* newHead=lessHead->next;
free(lessHead);
free(greaterHead);
return newhead;
}
|
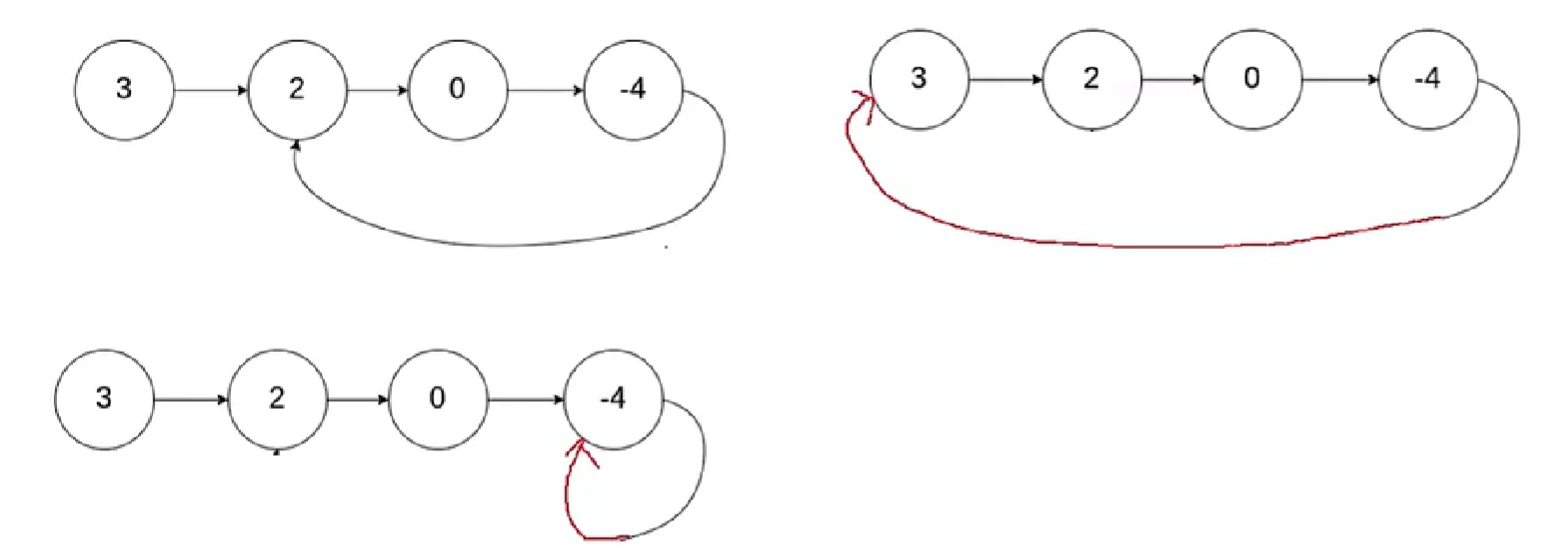
图一:初始步骤
图二:逻辑步骤
图三:逻辑结束
报错原因:
15本来指向4,现在4又指向12,无限循环,内存会超
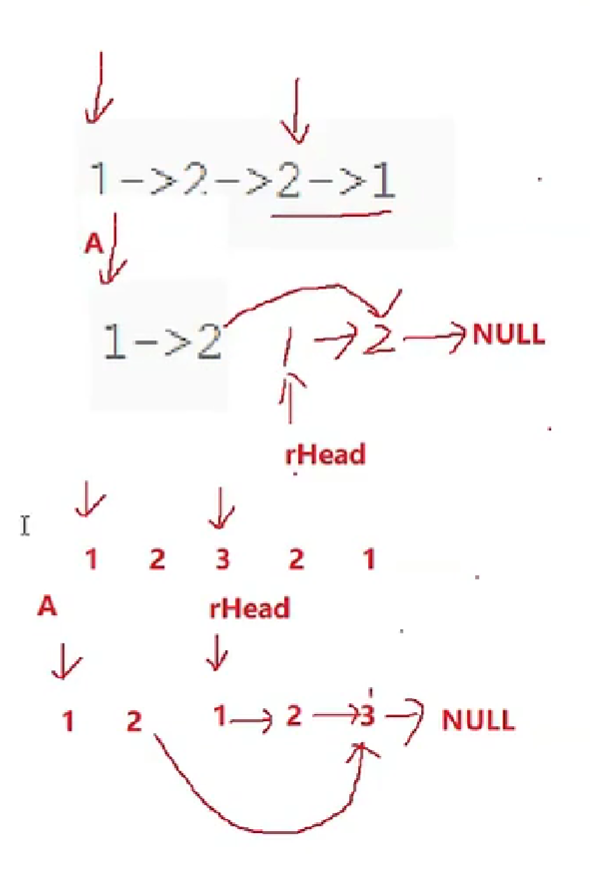
链表的回文结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
struct ListNode* middleNode(struct ListNode* head)
{
struct ListNode* mid=middleNode(A);
struct ListNode* rHead=reverseList(mid);
struct ListNode* curA=A;
struct ListNode* curR=rHead;
while(curA && curR)
{
if(curA->val!=curR->val)
{
return false;
}
else
{
curA=curA->next;
curR=curR->next;
}
}
}
|
不用断开原因本来中间的2就指向末尾的3(奇数情况),本来中间的2就指向末尾的1(偶数情况)
链表相交(一个节点只有一个next,只能聚合不能分散 )
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
struct ListNode *getIntersectionNode(struct ListNode *headB)
{
struct ListNode* tailA=headA;
struct ListNode* tailB=headB;
int lenA=1;
while(tailA->next)
{
++lenA;
tailA=tail->next;
}
int lenB=1;
while(tailB->next)
{
++lenB;
tailB=tailB->next;
}
if(tailA!=tailB)
{
return NULL;
}
int gap=abs(lenA-lenB);
struct ListNode* longList=headA;
struct ListNode* shortList=headB;
if(lenA<lenB)
{
shortList=headA;
longList=headB;
}
while(gap--)
{
longList=longList->next;
}
while(longList!=shortList)
{
longList=Longlist->next;
shortList=shortList->next;
}
retuen longList;
}
|
环形链表
带环的三种情况
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
|
bool hasCycle(struct ListNode *head)
{
struct ListNode* slow=head,*fast=head;
while(fast && fast->next)
{
slow=slow->next;
fast=fast->next->next;
if(slow==fast)
{
return true;
}
}
return NULL;
}
struct ListNode *detectCycle(struct ListNode* head)
{
struct ListNode* slow=head,*fast=head;
while(fast && fast->next)
{
slow=slow->next;
fast=fast->next->next;
if(slow==fast)
{
struct ListNode* meet=slow;
while(meet!=head)
{
meet=meet->next;
head=head->next;
}
return meet;
}
}
return NULL;
}
|
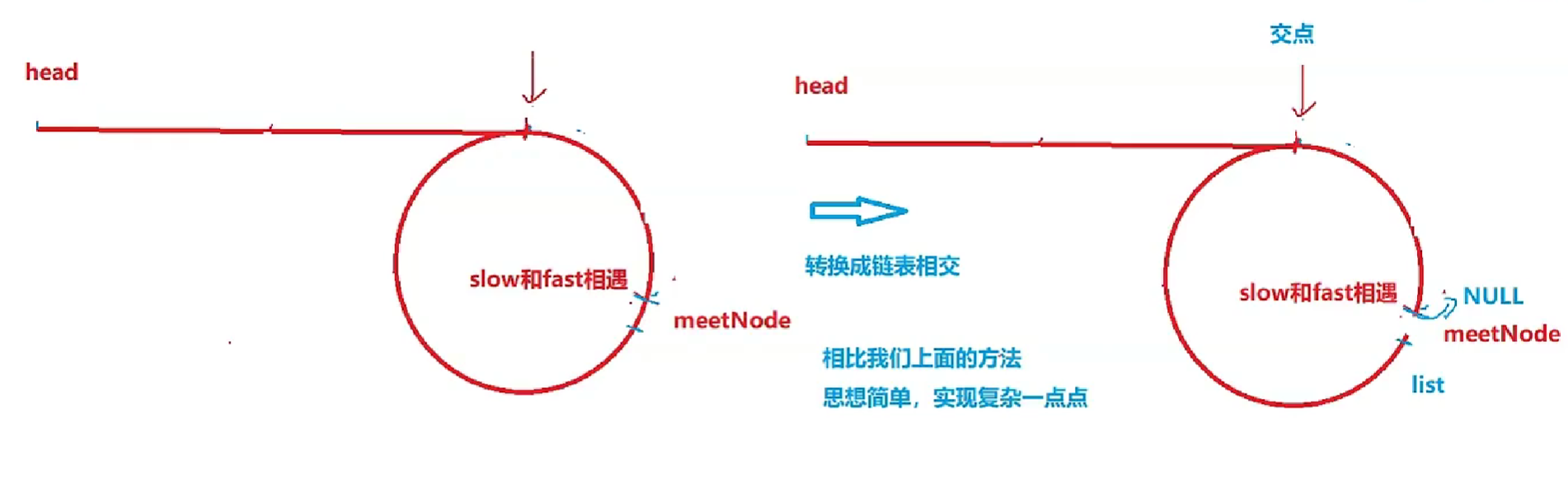
延伸问题:
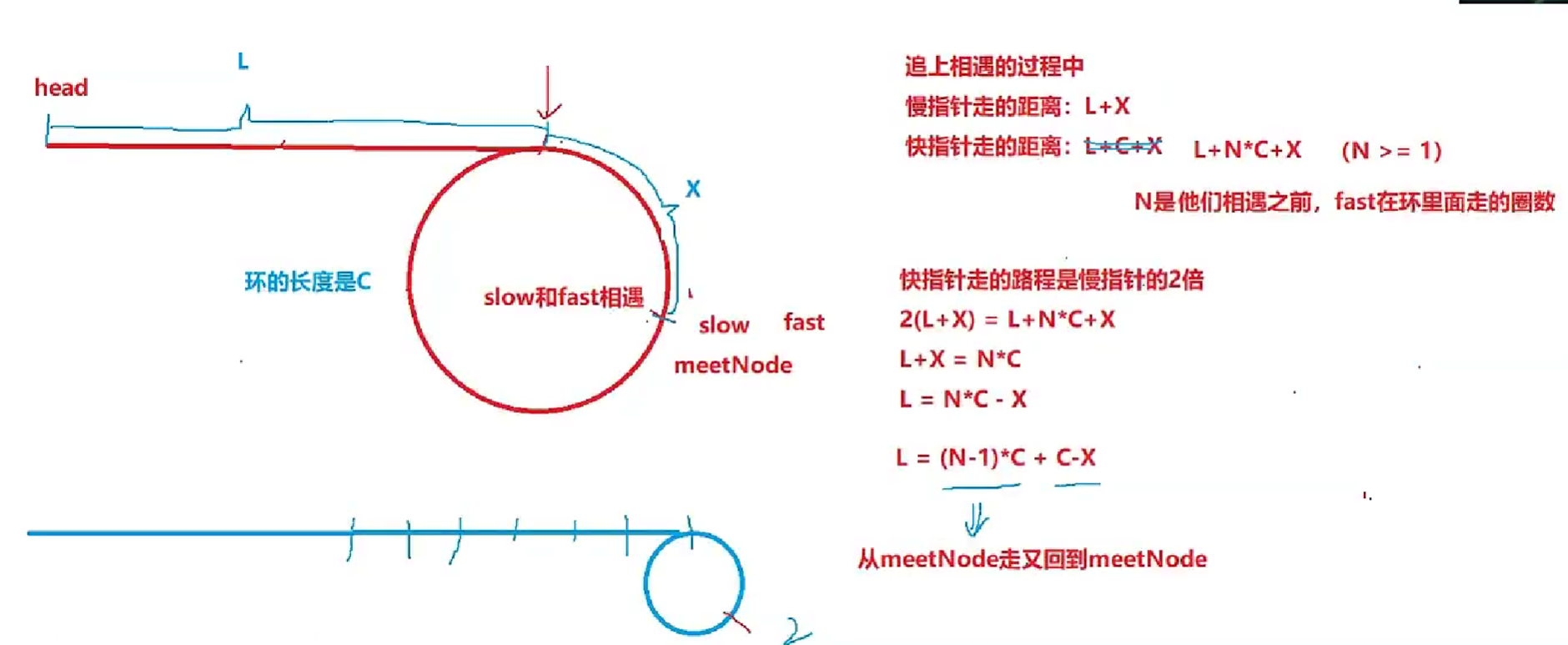
1.为什么slow和fast一定会在环中相遇?会不会在环里面错过,永远遇不上? 不会
- 第一步:slow和fast,fast一定先进环,这时slow走了入环前距离的一半
- 第二步:随着slow进环,fast已经在环里面走了一段,走了多少跟环的大小有关,假设slow进环的时候,slow跟fast的距离是N,fast开始追slow,slow每往前走一步,fast每次往前走两步,每追一次fast和slow的距离变化为N ,N-1,N-2,N-3,……,1,0 所以会相遇
2.为什么slow走一步,fast走两步?fast能不能一次走3,4,5…n? 结论:不一定会相遇
- 以fast走三步为例子
- N为偶数,每追一次fast和slow的距离变化为N ,N-1,N-2,N-3,……,1,0可以追上
- N为奇数 ,每追一次fast和slow的距离变化为N ,N-2,N-4,N-6,……,1,-1这一次追不上。距离变成-1意味着他们之间的距离变成C-1(C是环的长度)
- 如果C-1是奇数,那么就永远追不上了,陷入死循环
- 如果C-1是偶数,那么就可以追上
图一解决第一问
图二解决第二问
图三是第二个问题的第二种方法,转换为链表相交问题(相遇点下一个点为第二个链表的头节点,把相遇点滞空)
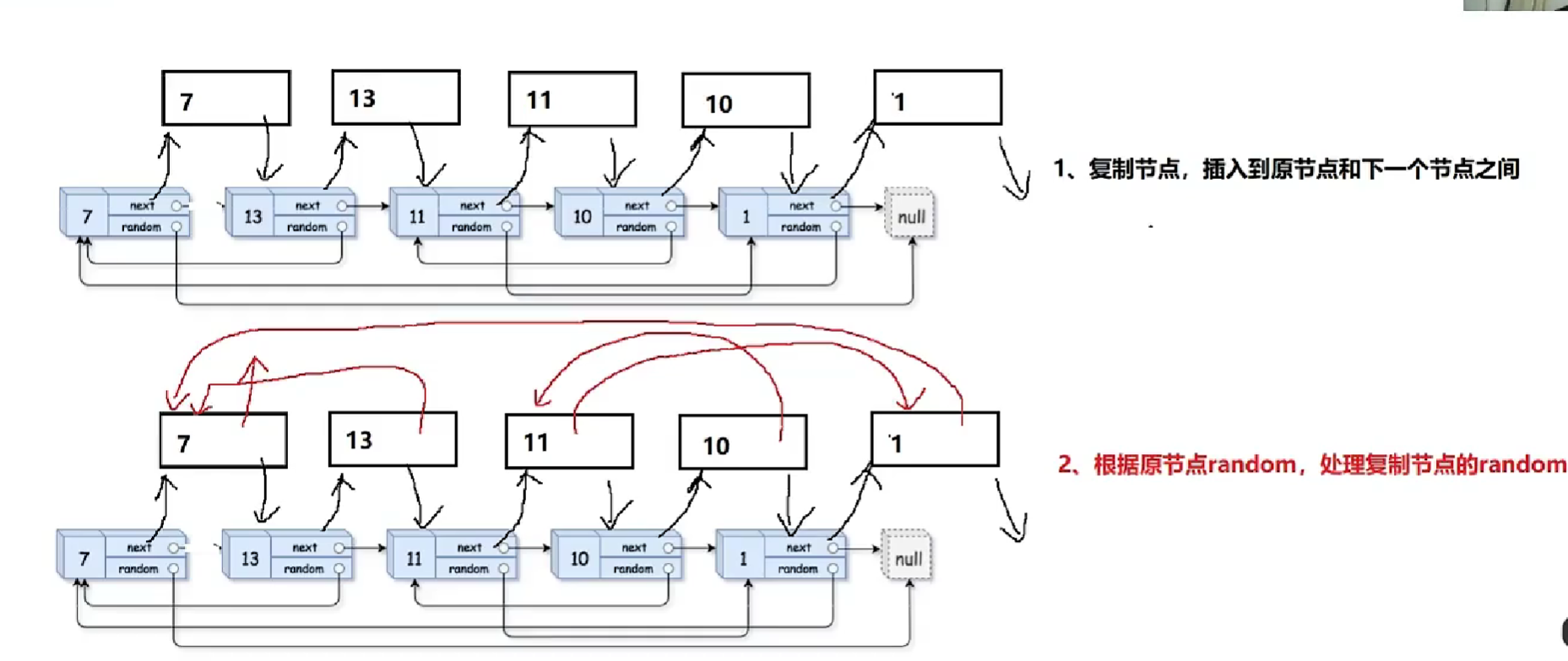
复制带随机指针的链表(复杂链表的复制)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
struct Node* copyRandomList(struct Node* head)
{
struct Node* cur=head;
while(cur)
{
struct Node* copy=(struct Node*)malloc(sizeof(struct Node));
copy->val=cur->val;
copy->next=cur->next;
cur->next=copy;
cur=copy->next;
}
cur=head;
while(cur)
{
struct Node* copy=cur->next;
if(cur->random==NULL)
{
copy->random=NULL;
}
else
{
copy->random=cur->random->next;
}
cur=copy->next;
}
struct Node* copyHead=NULL,*copyTail;
cur=head;
while(cur)
{
struct Node* copy=cur->next;
struct Node* next=copy->next;
if(copyTail==NULL)
{
copyHead=copyTail=copy;
}
else
{
copyTail->next=copy;
copyTail=copy;
}
cur->next=next;
cur=next;
}
return head;
}
|
3.复制节点解下来链接成一个新链表,恢复原链表链接关系
有效的括号 给定一个只包括‘(’ ,‘)’ ,‘[’ ,’]’ ,’{‘ ,‘}’的字符串s,判断是否有效 1.左括号必须和相同类型的右括号闭合2.左括号必须以正确的顺序闭合
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
bool isValid(char* s)
{
ST st;
StackInit(&st);
while(*s)
{
if((*s=='(' )
|| (*s=='[')
|| (*s=='{'))
{
StackPush(&st,*s);
++s;
}
else
{
if(StackEmpty(&st))
{
return false;
}
STDataType top=StackTop(&st);
StackPop(&st);
if(*s==')'&&top!='(' || *s==']'&&top!='[' || *s=='}'&&top!='{')
{
StackDestory(&st);
return false;
}
else
{
++s;
}
}
}
bool ret=StackEmpt(&st);
StackDestory(&st);
return true;
}
|
请你仅使用两个队列实现一个后入先出的栈,并支持普通栈的全部四种操作(不能改变队列的结构只能去调用队列提供的接口去实现)
- void push(int x)将元素x压入栈顶
- int pop( )移除并返回栈顶元素
- int top( )返回栈顶元素
- boolean empty( )如果栈是空的,返回true;否则返回false
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
|
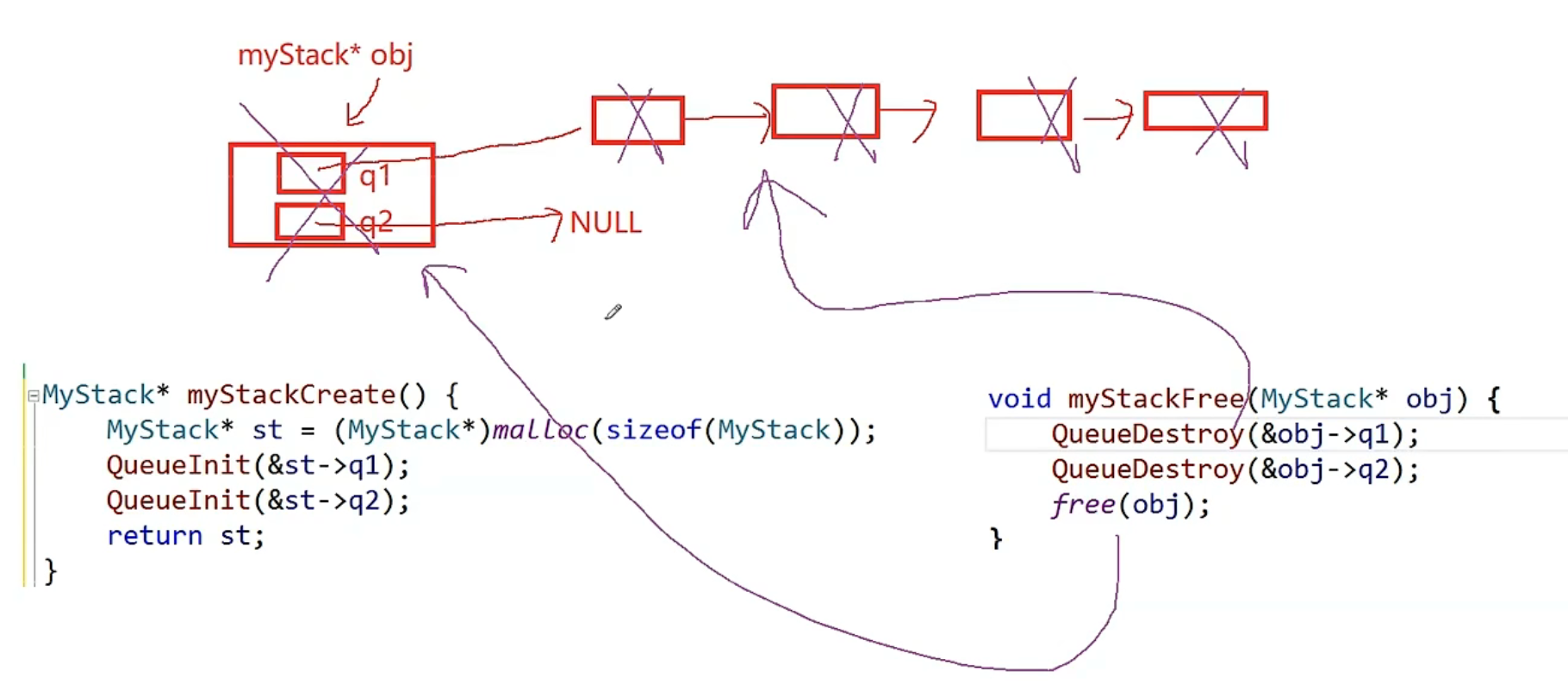
MyStack* myStackCreate()
{
MyStack* st=(Mystack*)malloc(sizeof(MyStack));
QueueInit(&st->q1);
QueueInit(&st->q2);
return st;
}
void myStackPush(MyStack* obj,int x)
{
if(!QueueEmpty(&obj->q1))
{
QueuePush(&obj->q1,x);
}
else
{
QueuePush(&obj->q2,x);
}
}
int MyStackPop(MyStack* obj)
{
Queue* emptyQ=&obj->q1;
Queue* noneemptyQ=&obj->q2;
if(!QueueEmpty(&obj->q2))
{
emptyQ=&obj->q1;
noneemptyQ=&obj->q2;
}
while(QueueSize(noneemptyQ)>1)
{
QueuePush(emptyQ,QueueFront(noneempty(Q)));
QueuePop(noneemptyQ);
}
int top=QueueFront(noneemptyQ);
QueuePop(noneemptyQ);
return top;
}
int MyStackTop(Mystack* obj)
{
if(!QueueEmpty(&obj->q1))
{
return QueueBack(&obj->q2);
}
else
{
return QueueBack(&obj->q2);
}
}
bool myStackEmpty(MyStack* obj)
{
return QueueEmpty(&obj->q1)&& QueueEmpty(&obj->q2);
}
void myStackFree(MyStack* obj)
{
QueueDestory(&obj->q1);
QueueDestory(&obj->q2);
free(obj);
}
|
用栈实现队列
- void push(int x)将元素x推到队的队尾
- int pop( )从队列的开头移除并返回元素
- int peak( )返回队列开头的元素
- boolean empty( )如果队列为空,返回true,否则false
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
void myQueuePush(MyQueue* obj,int x)
{
StackPush(&obj->pushST,x)
}
int myQueuePop(MyQueue* obj)
{
if(StackEmpty(&obj->popST))
{
while(!StackEmpty(&obj->push))
{
StackPush(&obj->popST,StackTop(&obj->pushST));
StackPop(&obj->pushST);
}
}
int front=StackTop(&obj->popST);
StackPop(&obj->popST);
return front;
}
int myQueuePeek(MyQueue* obj)
{
if(StackEmpty(&obj->popST))
{
while(!StackEmpty(&obj->push))
{
StackPush(&obj->popST,StackTop(&obj->pushST));
StackPop(&obj->pushST);
}
}
return StackTop(&obj->popST);
}
bool myQueueEmpty(MyQueue* obj)
{
return StackEmpty(&obj->pushST) && StackEmpty(&obj->popST);
}
|
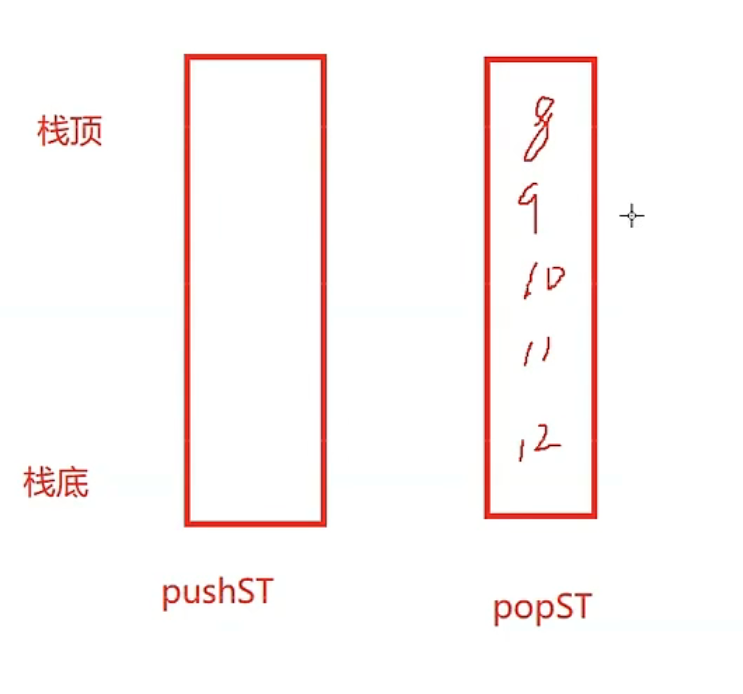
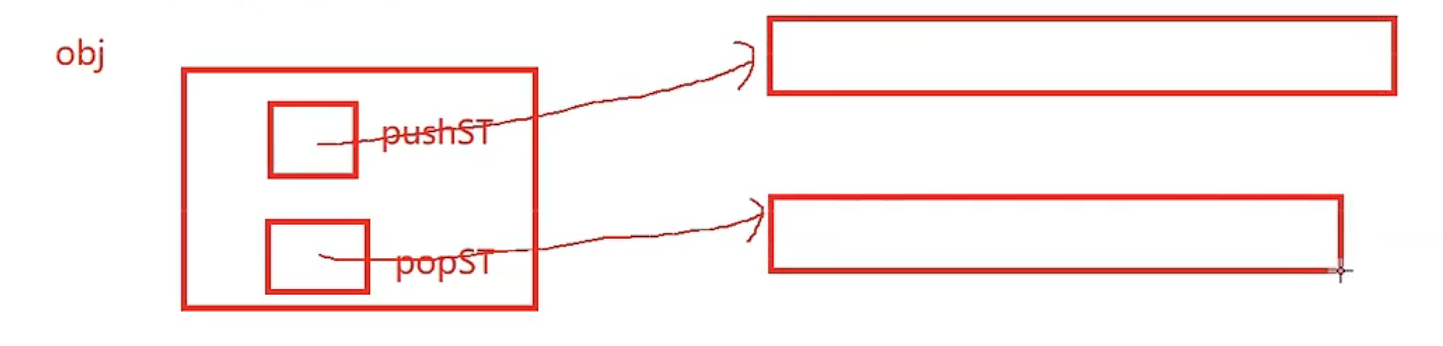
上图为逻辑图,下图为结构图(obj和两个栈,popST和pushST的关系)
循环队列
- MyCircleQueue(k):构造器,设置队列长度为k
- Front:从对首取元素,如果队列为空,返回-1
- Rear:获取队尾元素,如果队列为空,返回-1
- enQueue(value):向循环队列插入一个元素,如果成功插入返回true
- deQueue( ):从循环队列中删除一个元素,如果成功返回真
- isEmpty( ):检查循环队列是否为空
- isFull( ):检查队列是否已满
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
|
typedef struct
{
int* a;
int front;
int tail;
int k;
}MyCircularQueue;
MyCircularQueue* myCircularQueueCreate(int k)
{
MyCircularQueue* cq=(MyCircularQueue*)malloc(sizeof(MyCircularQueue));
cq->a=(int*)malloc(sizeof(int)*(k+1));
cq->front=cq->tail=0;
cq->k=k;
return cq;
}
bool MyCircularQueueIsEmpty(CircularQueue* obj)
{
return obj->front==obj->tail;
}
bool MyCircularQueueIsFull(CircularQueue* obj)
{
return (obj->tail+1)%(obj->k+1)==obj->front;
}
bool MyCircularQueueEnQueue(CircularQueue* obj,int value)
{
if(MyCircularQueueIsFull(obj))
return false;
obj->a[obj->tail]=value;
++obj->tail;
obj->tail %= (k+1);
}
bool MyCircularQueueDeQueue()
{
if(MyCircularQueueIsEmpty(obj))
return false;
++obj->front;
obj->front %= (k+1);
return ture;
}
int MyCircularQueueFront(MyCircularQueue* obj)
{
if(myCircularQueueIsEmpty(obj))
return -1;
return obj->a[onj->front];
}
int MyCircularQueueRear(MyCircularQueue* obj)
{
if(myCircularQueueIsEmpty(obj))
return -1;
if(obj->tail == 0)
return obj->a[k];
else
return a[obj->tail-1];
}
|
重点:循环队列,无论使用数组实现还是循环链表实现,都要多开一个空间,也就意味着要是一个存k个数据的循环队列,要开k+1个空间,否则无法实现判空和判满,避开空和满是相同的情况