数学建模算法入门(2)
TOPSIS算法
评价方法大体可以分为两类,其主要区别在确定权重的方法上。一类是主观赋权法,如综合指数法,模糊综合评判法,层次分析法,功效系数法等。另一类是客观赋权,根据各项指标间相关关系或各指标值变异程度确定权数,如主成分分析法,因子分析法,理想解法(也称TOPSIS法)
topsis:构造评价问题的正理想解和负理想解方法:设多属性决策方案集(待评价方案集)为D={d_1,d_2,…,d_m}衡量方案优劣的属性变量为x_1,x_2,…x_n这时方案集D中的每个方案d_i(i=1,…,m)的n个属性值构造的向量是[a_i1,…,a_in],它作为n维空间中的一个点,能唯一地表征方案d_i。
算法步骤:
消除量纲问题:用向量规划的方法求得规范决策矩阵,设多属性决策问题的决策矩阵$A=(a{ij}){m×n}$,规范化决策矩阵$B=(b{ij}){m×n}$,其中$b{ij}=a{ij}/\sqrt{\sum{i=1}^{m}{a{ij}^{2}}}$,i=1,2,…,m;j=1,2,…,n。
权重问题:由决策人给定各属性的权重向量为$w=[w1,w_2,…,w_n]$,则$c{ij}=wj·b{ij},i=1,2,…,m;j=1,2,…,n$
属性的权重值乘以每一个数据值就是最终的评价值确定正理想解$C^$和负理想解$C^0$,设正理想解的第j个属性值为$C_j^$,负理想解第j个属性值为$C_j^0$
计算各方案到正理想解与负理想解的距离
计算各方案的排队指标值$f_i^=s_i^0/s_i^+s_i^0$越大越好
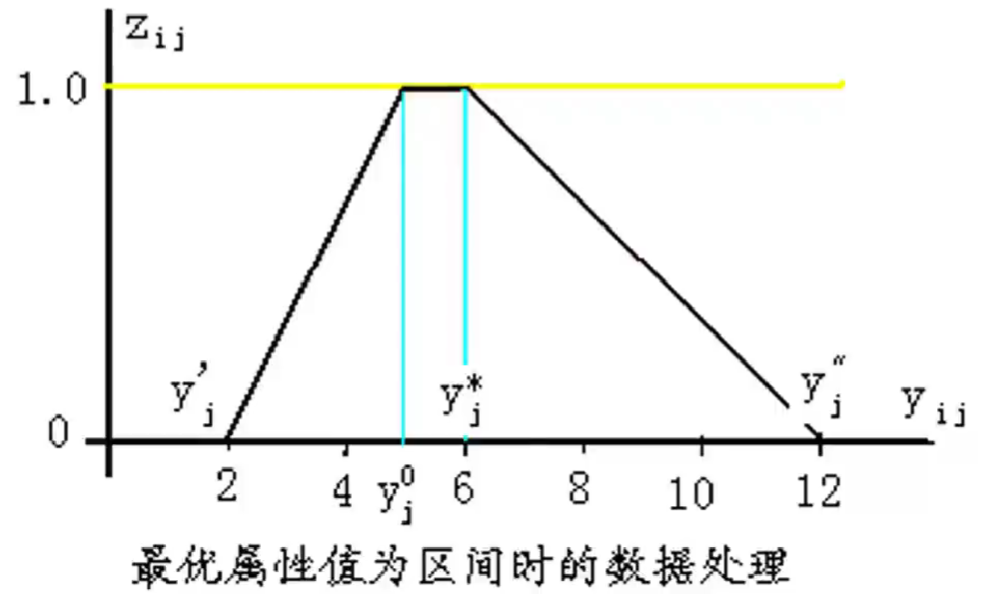
例题1.1为了客观地评价我国研究生教育的实际状况和各研究院的教学质量,国务院学位委员会办公室组织过依次研究生院的评估
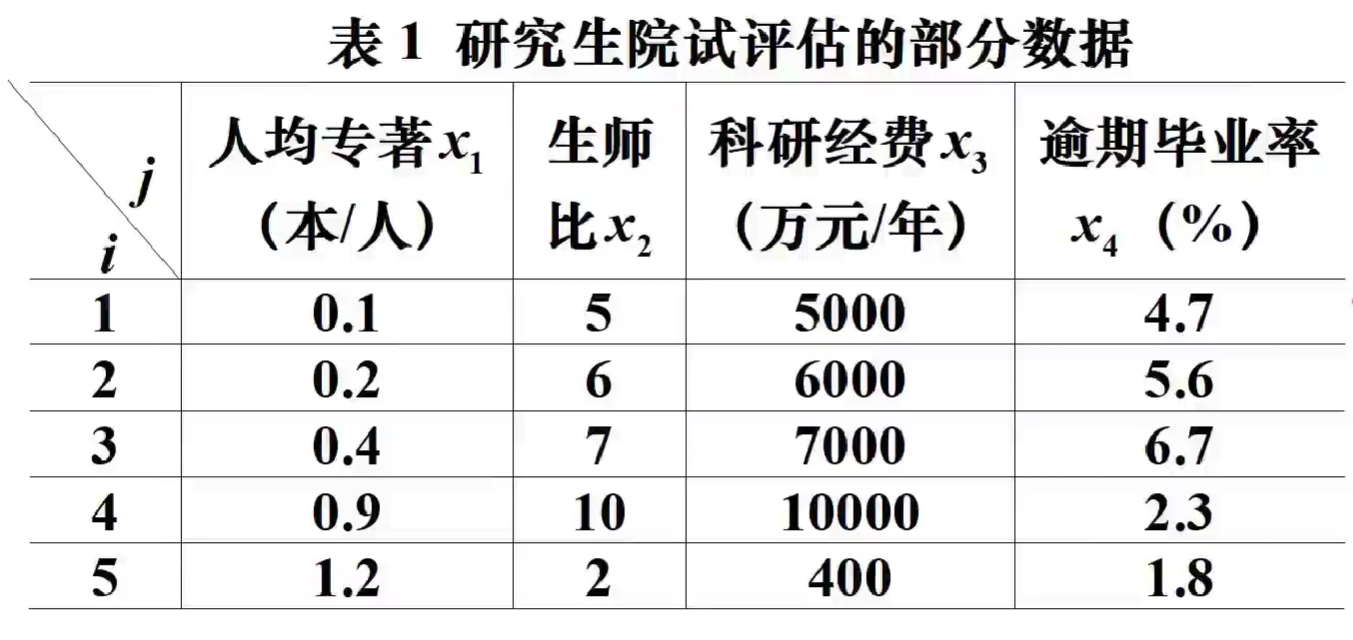
第一步:属性值的规范化—->标准的0-1变换(为了使每个属性变换后的最优值为1且最差值为0)——>全变成效益型
对效益性属性
对成本型属性
对于区间型,设定最优属性区间为$[a_j^0,a_j^*],a_j^{‘’}为无法容忍上限,a_j^{‘}为无法容忍下限$
1 | clc,clear |
注意:这里其实是两种方法1.可以先都变成效益型的然后用向量规划的那个式子算2.之间用向量规划算,但是成本型的要将算出 来的b_ij变成1-b_ij。前提是没有区间型,要是有区间型就要先把区间型变成效益型。
聚类分析
- R型聚类作用:降维处理,将原来的变量变为某一个或某几个变量
- Q型聚类作用:分类及分析(常用)
样品间的相似度量——距离
欧式距离 pdist(x)绝对距离 pdist(x,’cityblock’) (几乎不用)
明氏距离 pdist(x,’minkowski’,m)
切氏距离 max(abs(xi-xj))
方差加权距离,将原数据标准化以后的欧式距离
马氏距离 pdist(x,'mahal')
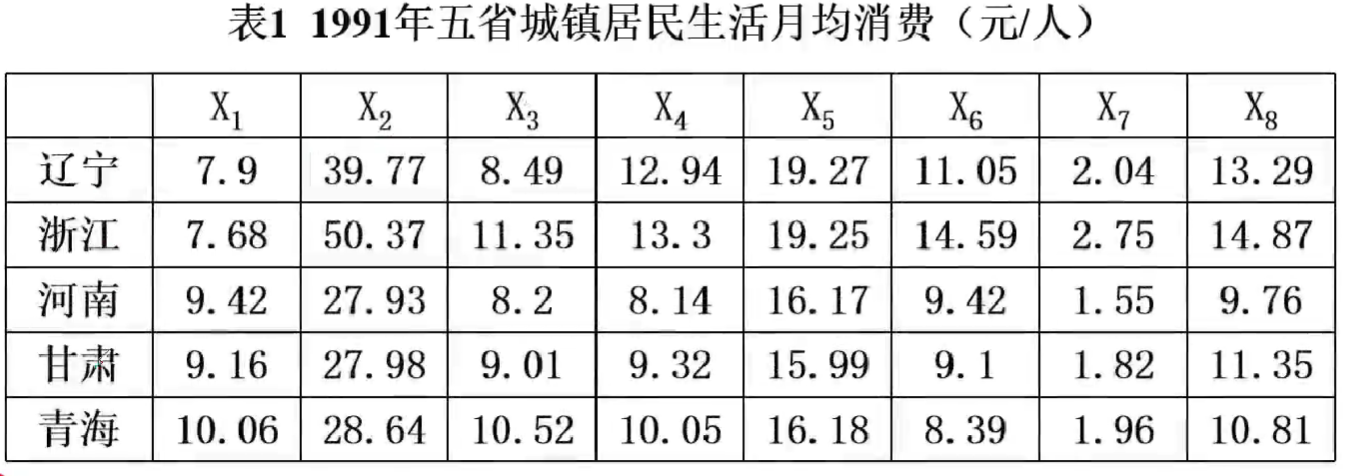
例题1.1为了研究辽宁,浙江,河南,甘肃,青海五省1991年城镇居民生活消费规律,需要利用调查资料对五个省进行分类,指标变量共8个,意义如下:x1:人均粮食支出,x2:人均副食支出,x3:人均烟酒茶叶支出,x4:人均其他副食支出,x5:人均衣着商品支出,x6:人均日用品支出,x7:人均燃料支出,x8:人均非商品支出
1 | d1=pdist(a)%此时计算出各行之间的欧式距离,为了得到书中的距离矩阵,我们输入命令 |

类间距离
d_ij表示两个样品x_i,x_j之间的距离,G_p,G_q分别表示两个类别,各自含有n_p,n_q个样品
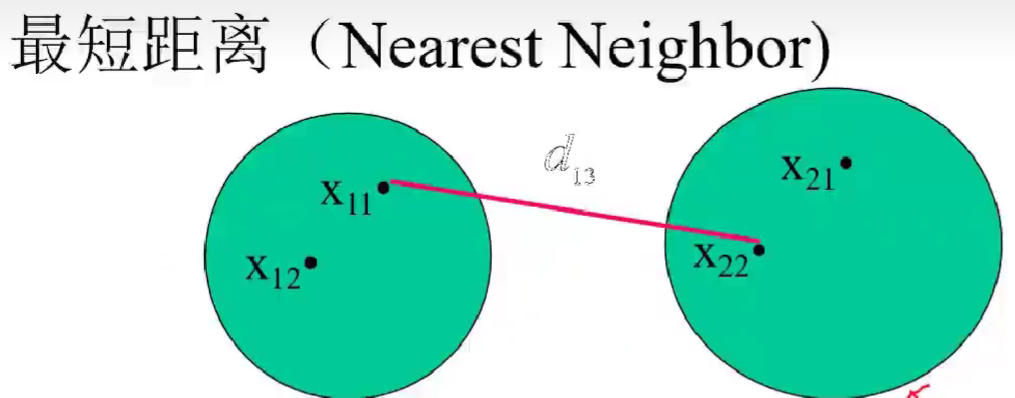
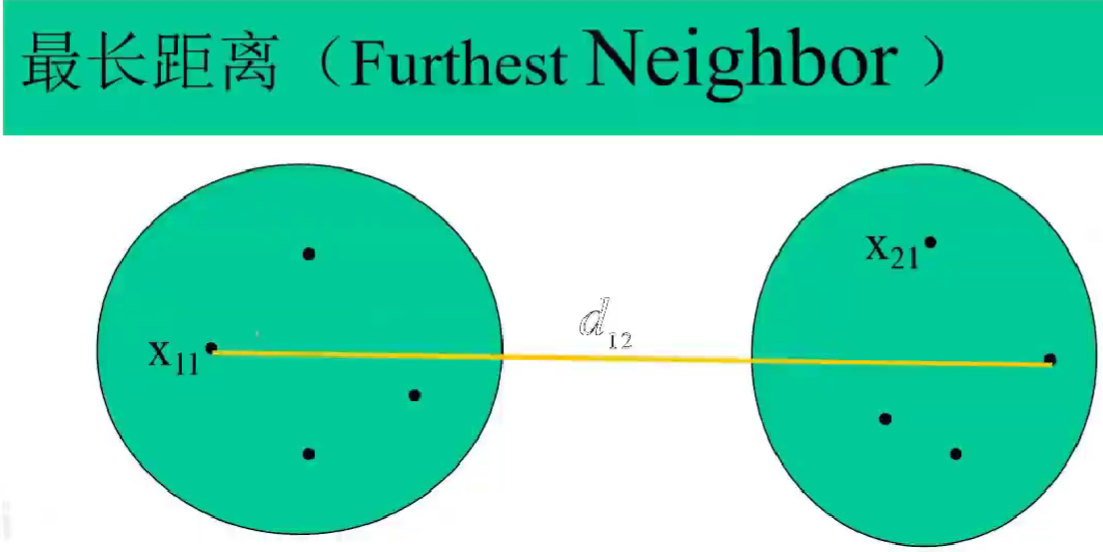
常见聚类方法的步骤
谱系聚类法
1.选择样本间距离的定义(一般为欧氏距离)及类间距离的定义(一般为最短距离)
2.计算n个样本两两间的距离,得到距离矩阵D=(d_ij)
3.构造个类,每类只含有一个样本
4.合并符合类间距离定义要求的两个类作为一个新类
5.计算新类与当前各类的距离。若类的个数为1,则转到步骤6,否则回到步骤4
6.画出聚类图
7.决定类的个数和类
例题1.1.2为了研究辽宁等5省1991年成长居民生活消费情况的分布规律,根据调查资料做类型分类,用最短距离做类间分类,数据如表1
将每个省视为一个样品,先计算5个省区之间的欧氏距离,用D0表示距离矩阵(前一问已经构建出来),可得:
1 | (1) (2) (3) (4) (5) |
D0(3,4)=2.20最小因此要把3,4合并为一类,为类6,代替了3,4两类。
类6与剩余的1,2,5之间的距离分别为:
d(3,4)_1=min(d31,d41)=min(13.80,13.12)=13.12
d(3,4)_2=min(d32,d42)=min(24.63,24.06)=24.06
d(3,4)_5=min(3.51,2.21)=min(3.51,2.21)=2.21
得到一个新矩阵:
1 | D1: |
D1(6,5)=2.21最小因此要把6,5合并成一类,为类7,代替了6,5两类
类7与剩余的1,2之间的距离分别为:
d(5,6)_1=min(d51,d61)=min(12.80,13.12)=12.80
d(5,6)_2=min(d52,d62)=min(23.54,24.06)=23.54
再得到一个新矩阵:
1 | D2: |
D2(1,2)=11.67最小因此要把1,2合并成一类,为类8,代替了1,2两类
此时,我们有两个不同的类,类7和类8,它们的距离
d(7,8)=min(d71,d72)=min(12.80,23.54)=12.80
最后得到新矩阵:
1 | G7 G8 |
最后合并成一个大类。
1 | %谱系聚类的MATLAB实现 |
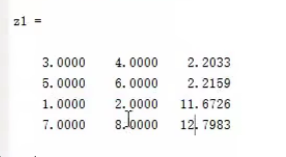
以下为z1=linkage(d)的聚类结果
K-平均聚类法
- 从n个数据对象任意选择k个对象作为初始聚类中心
- 循环3和4直到每个聚类不再发生变化为止
- 根据每个聚类对象的均值(中心对象),计算每个对象与这些中心对象的距离,并根据最小距离重新对相应对象进行分析(第一次中心对象是指定的,之后中心对象是分配到每个类的对象的平均值,进行不断的更新中心对象)
- 重新计算每个(有变化)聚类的均值(中心对象)
注意:只适应于聚类均值有意义的场合,当数据集中包含符号属性时,直接应用k-means算法就有问题;用户必须事先指定k的个数;对噪声和孤立点数敏感,少量的该类数据能够对聚类均值起到很大影响;刚开始取中心对象可以不是样本点
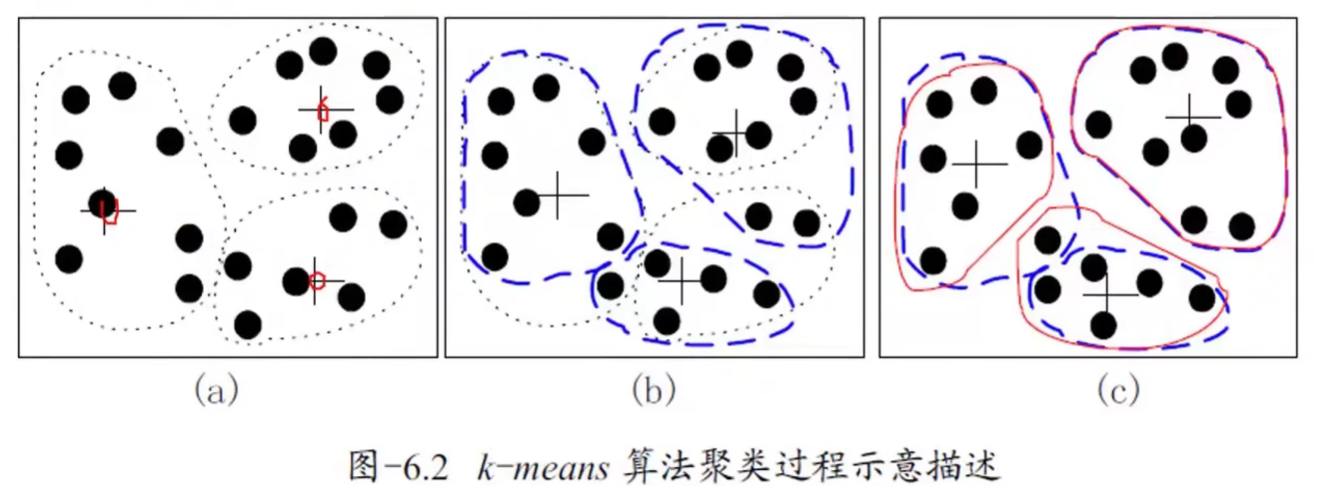
例题1.2假设空间数据对象分布如图(a)所示,设k=3,也就是需要将数据集划分为三份(聚类)
1 | clear all |
变量间的相似度量——相似系数
当对p个指标变量进行聚类时,用相似系数来衡量变量之间的相似程度(关联度),若用 $C_{\alpha \beta}$表示变量之间的相似系数,则应满足
两个变量完全相似(一个变量由另一个变量乘以一个整数得到),此时相似系数为1
相似系数中最常用的是相关系数与夹角余弦
- 两变量的夹角余弦定义为
- 两变量的相关系数定义
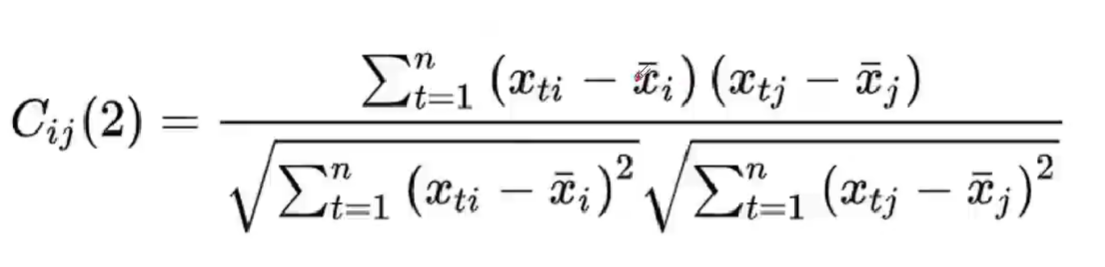
计算例题1中各指标之间的相关系数与夹角余弦
1 | a=[7.9 39.77 8.49 12.94 19.27 11.05 2.04 13.29 |
GM(1,1)灰色预测
灰色预测法用等时距观测到的反应预测对象特征的一系列数量值构造灰色预测模型,预测未来某一时刻的特征值,或达到某一特征量的时间
灰色预测的四种常见类型
- 灰色时间序列预测:即用观察到的反映预测对象特征的时间序列来构造灰色预测模型,预测未来某一时刻的特征量,或达到某一特征量的时间
- 畸变预测:即通过灰色模型预测异常值出现的时刻,预测异常值什么时候出现在特定时区内(异常气候,预测零件问题时间)
- 系统预测:通过对系统行为特征指标建立一组相互关联的灰色预测模型,预测系统中众多变量之间的相互协调关系的变化(用的次数比较少)
- 拓扑预测:将原始数据做曲线,在曲线上按定值寻找该定值发生的所有时点,并以该定值为框架构成时点数列,然后建立模型预测该定值所发生的时点
灰色关联度:
$\zeta_i(k)=\frac{min_imin_k|X_0(k)-X_i(k)|+\rho max_imax_k|X_0(k)-X_i(k)|}{|X_0(k)-X_i(k)|+\rho max_imax_k|X_0(k)-X_i(k)|}$
$X_0(k)表示标准数列中的第k个元素,例如:x_0(1)为标准列中的第一个元素\假设有m个比较数列X_i(k)表示第i个数列中的第k个元素(i=1,2,…,m),\rho一般取0.5$
$上述式子中min_imin_k|X_0(k)-X_i(k)|表示先找出每个比较数列中的每个元素和标准数列中每个元素差值的最小值再找出这些元素中的最小值$
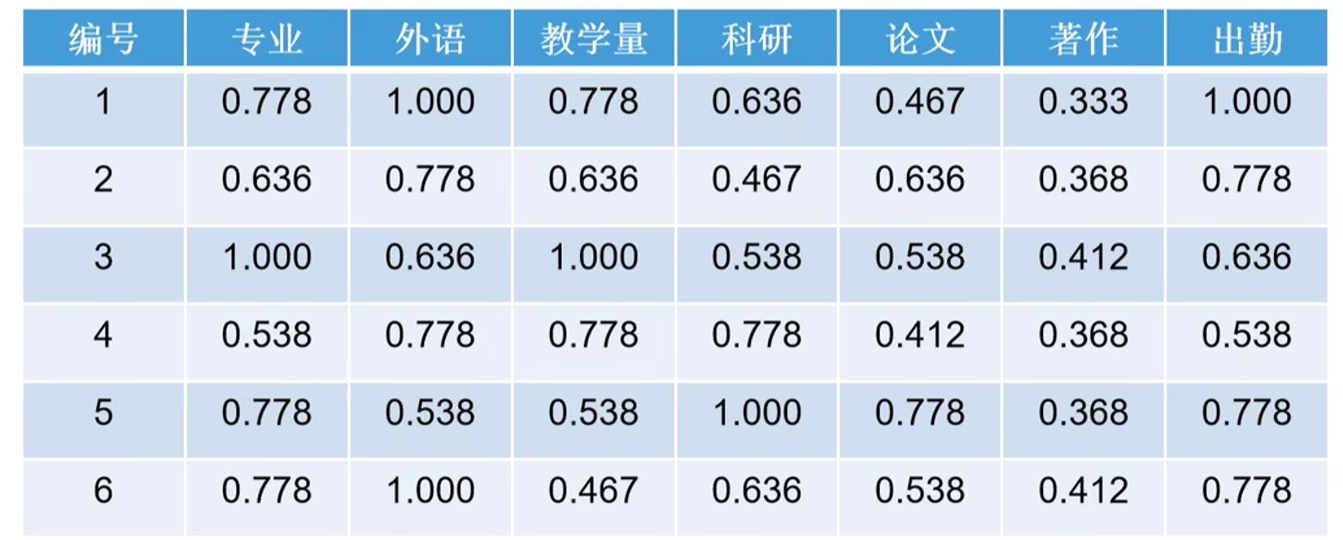
例题利用灰色关联分析对6位教师工作状况进行综合分析
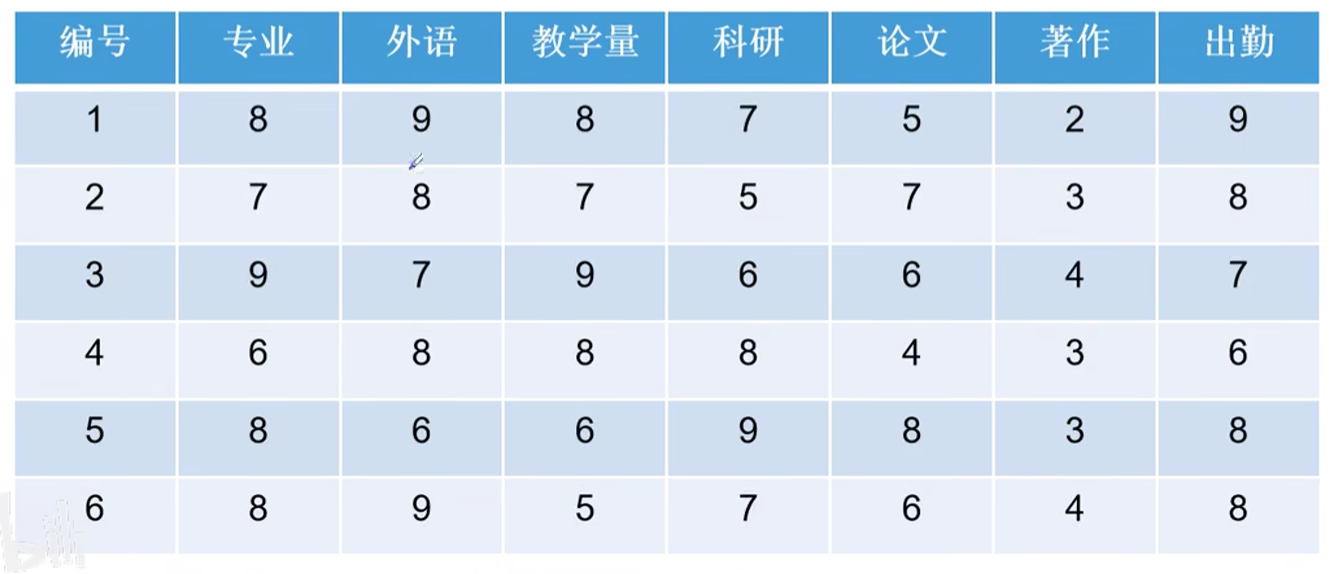
1.确定参考数列{x_0}={9 9 9 9 8 9 9}
2.计算$|x_0(k)-x_j(k)|$见下表
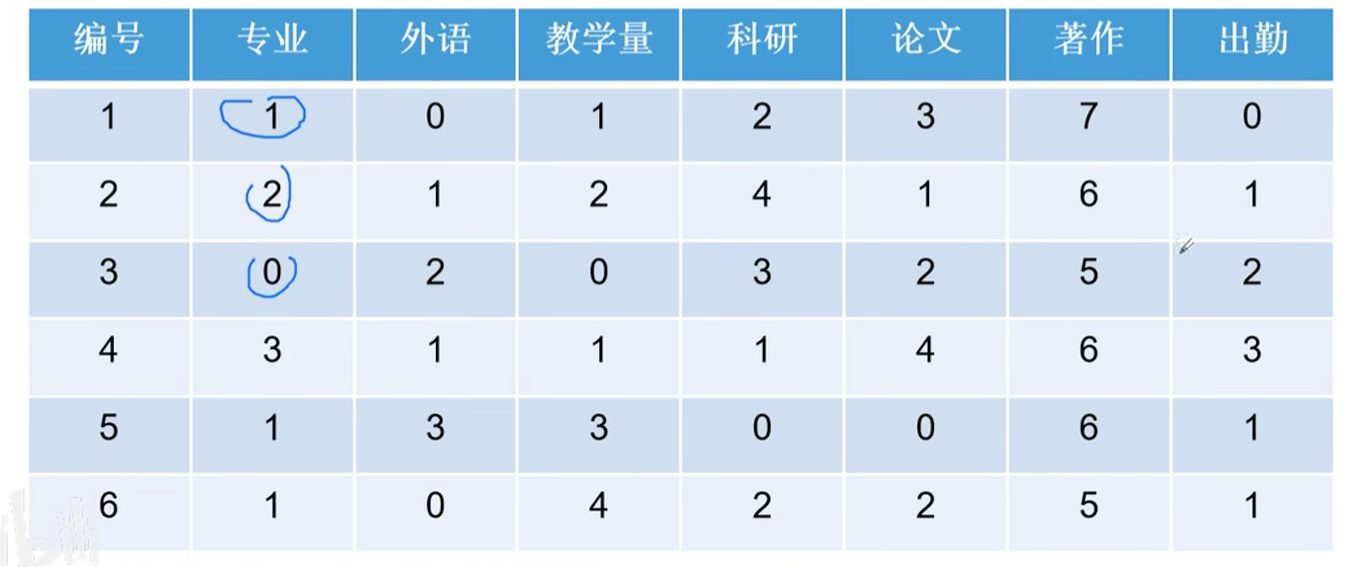
3.求最值
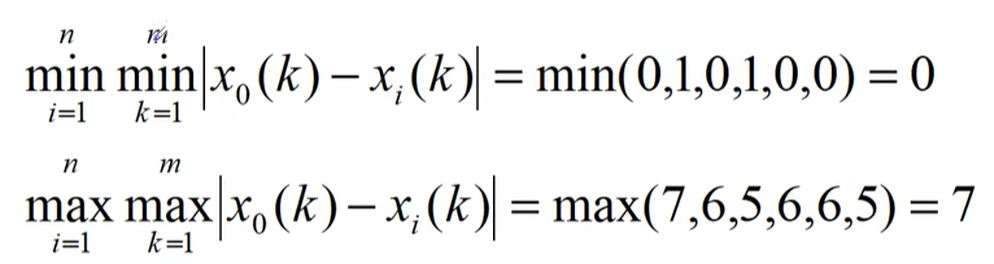
4.带入上述公式得
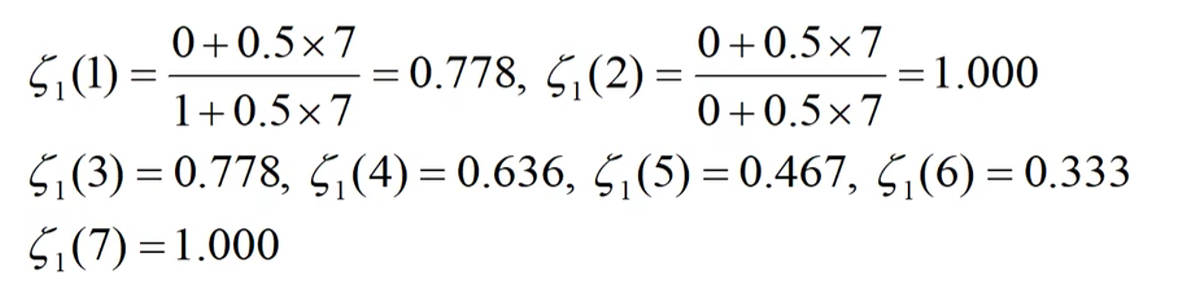
注意:这里给出的只有第一个老师的数据还要求$\zeta_2(k),\zeta_3(k)…,\zeta_6(k)其中k=1,2,…,7$结果如下
5.分别计算每个人各指标关联系数的均值(关联序):
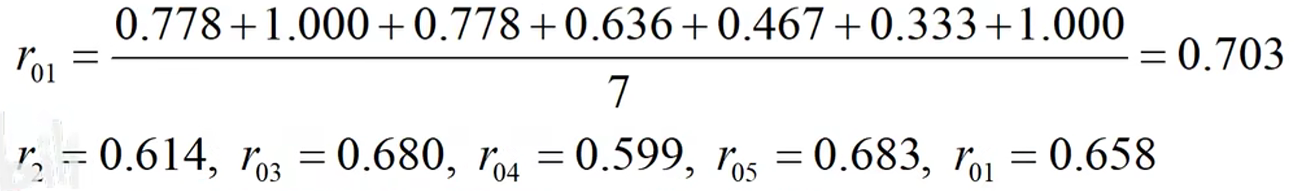
灰色生成数列:一切灰色序列都能通过某种生成弱化其随机性,显现其规律性。数据生成的常用方式有累加生成,累减生成,和加权累加生成
注意:从这里的记号可以看到,从原始数列x(0)得到新数列x(1),在通过累减生成可以还原出原始序列。$实际运用在数列x^{(1)}的基础上预测出x^{(<1>)},通过累减生成得到预测数列x^{0}$
灰色生成数列的后续构建函数由微分函数构成
定义累加后数列x(1)的灰导数为:$d(k)=x^{(0)}{k}=x^{(1)}(k)-x^{(1)}(k-1)$
定义邻值生成后数列z(0)的灰导数为:$x^{(0)}{k}+az^{(1)}(k)=b,其中x^{(0)}为灰导数a为发展系数,z^{(1)}{(k)}称为白化背景值,b称为灰作用量$灰色导数方程中只有a和b两个未知量但是实际给的方程预测点很多,这样就存在多余方程和多余解——-用最小二乘法求解多余解
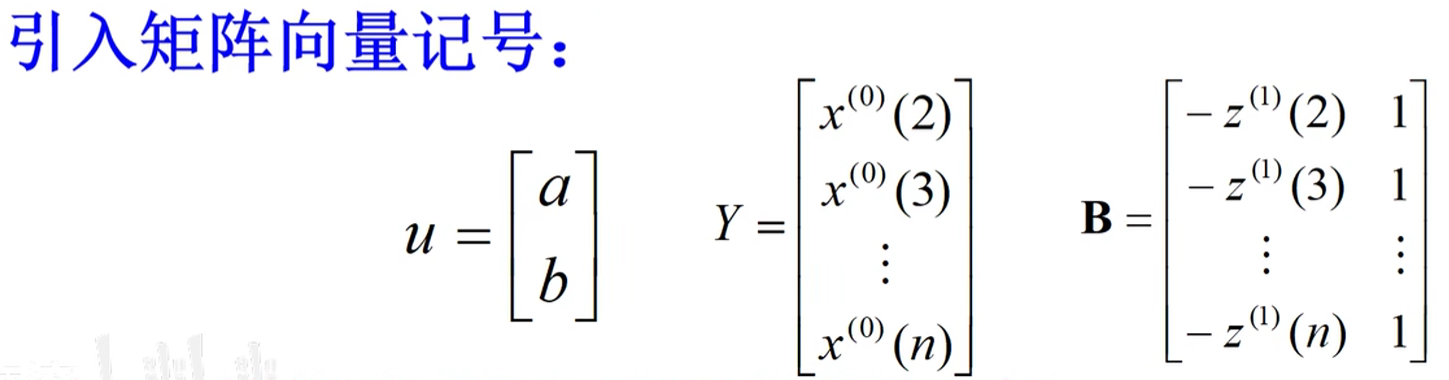
最小二乘得到:$u^T=(a,b)^T=(BB^T)^{-1}B^TY$
GM(1,1)灰色预测的步骤
数据的检验与处理
构造数据矩阵B和数据向量Y
这里用一个例题来说明:

数据矩阵B的构造方法:
对原始序列做一次累加:
用加权临值生成:这里$\alpha=0.5,Y=\alpha(x^{(1)}(1)+x^{(1)}(2))…$
最后得到:Y和B
其中a,b用最小二乘法得到:
建立GM(1,1)模型
得到预测
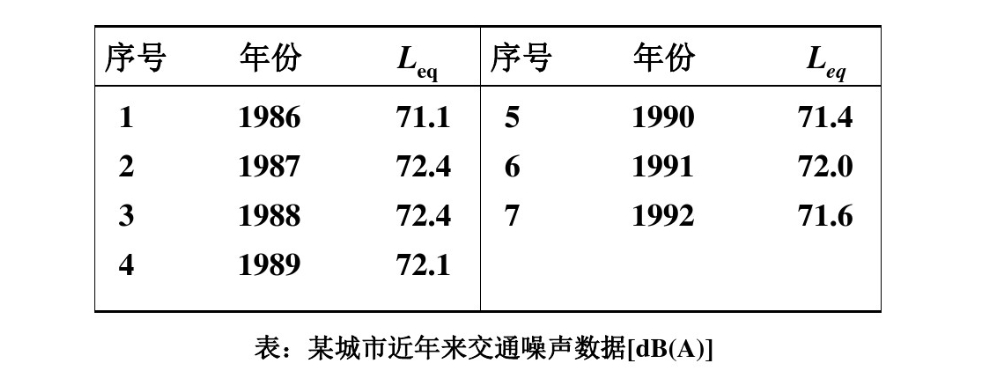


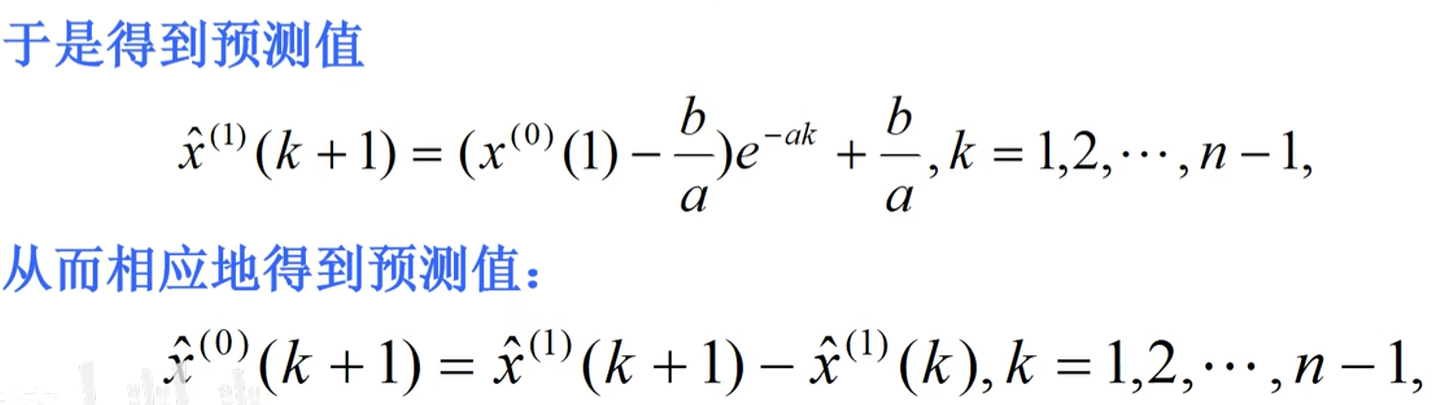
其中x^^(1)^(1)=x^^(0)^(1)=x^(1)^(1)=71.1得到:x^^(1)^(k+1)=-30928.85259e^-0.00234379k^+30999.95259
插值与拟合基本原理
插值问题(已知函数在某区域内若干点处的值,求函数在该区间内其他点处的值)
注意因为Runge不应该使用七次以上的差值,为避免这一现象常用的方法是:将差值区间分成若干小区间,在小区间内用低次差值
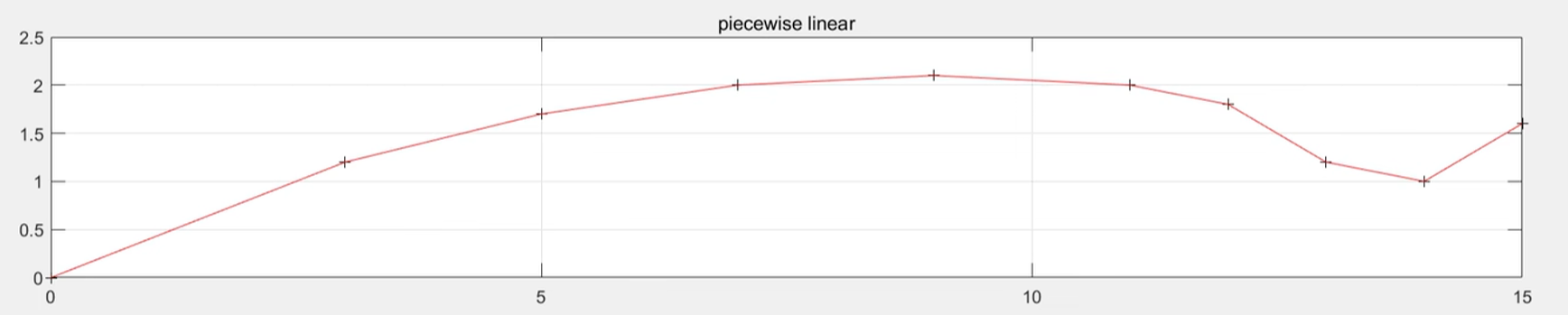
例题1.1在一天24小时内,从零点开始每间隔2小时测得的环境温度数据分别为12,9,9,10,18,24,28,27,25,20,18,15,13推测中午1点温度,并作出24小时温度变化曲线图
matlab差值
- 一维插值命令是interp1,其基本格式是$yi=interp1(x,y,xi,’method’)$,其中x,y为已知点坐标,xi为要差值点,通常x,y,xi为向量,’method’表示插值方法:’nearest’为最邻近插值,’linear’为线性插值,’spline’为三次样条插值,’cubic’为立法插值,缺省为线性插值
1 | x=0:2:24; |
1 | function plane |
- 二维插值命令是interp2,基本格式为$zi=interp2(x,y,z,xi,yi,’method’)$x,y,z为插值点,z可以理解为被插值函数在(x,y)处的值,xi,yi为被插值点,zi为输出的插值结果,可以理解为插值函数在(xi,yi)处的值,x,y为向量,xi,yi为向量或矩阵,而z和zi则为矩阵,’method’表示插值方法:’nearest’为最邻近插值,’linear’为双线性插值,’spline’为双三次样条插值,默认为线性
1 | x=1:5; |
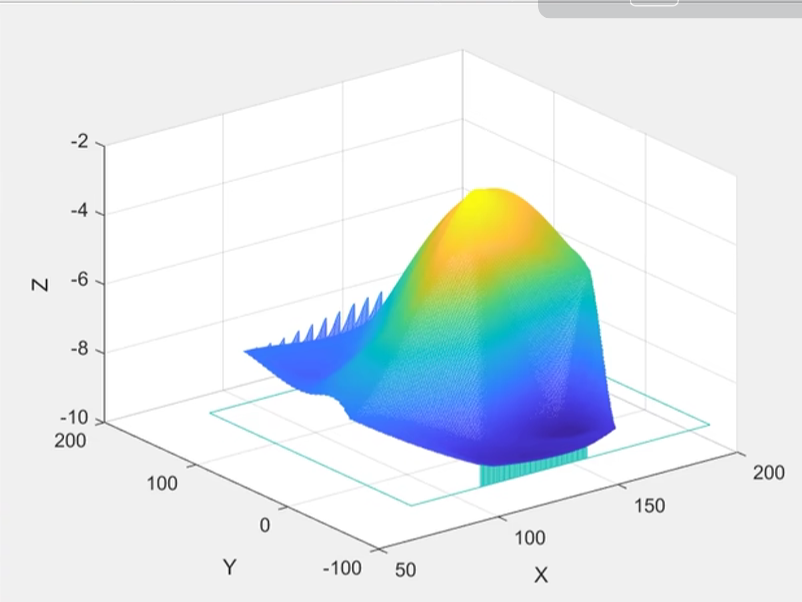
例题1.2在某山区测得一些地点的高程如下表,平面区域为0<x<5600,0<y<4800,用matlab中的最邻近邻值,双线性插值和双三次插值三种方法作出该山区的地貌图和等高线图,并求出最高点和最低点
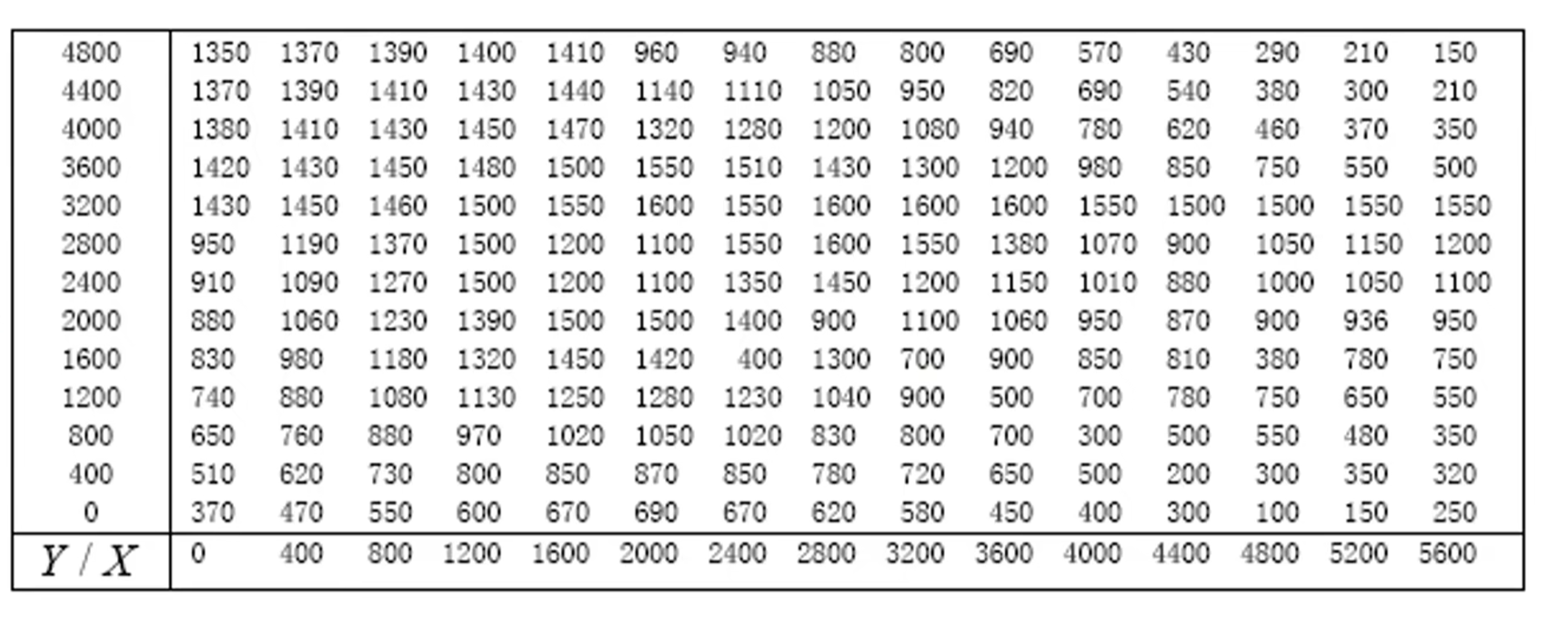
1 | x=0:400:5600; |
注意:前面讨论的插值问题的插值点(x,y)均为网格点,当(x,y)为散乱点时可用$griddata(x,y,z,xi,yi,’method’)$进行二维插值
例题1.3在某海域测得一些点(x,y)处的水深如下表,船的吃水深度为5英尺,在矩形区域(75,200)*(-50,150)内的哪些地方船要避免进入

1 | clear |
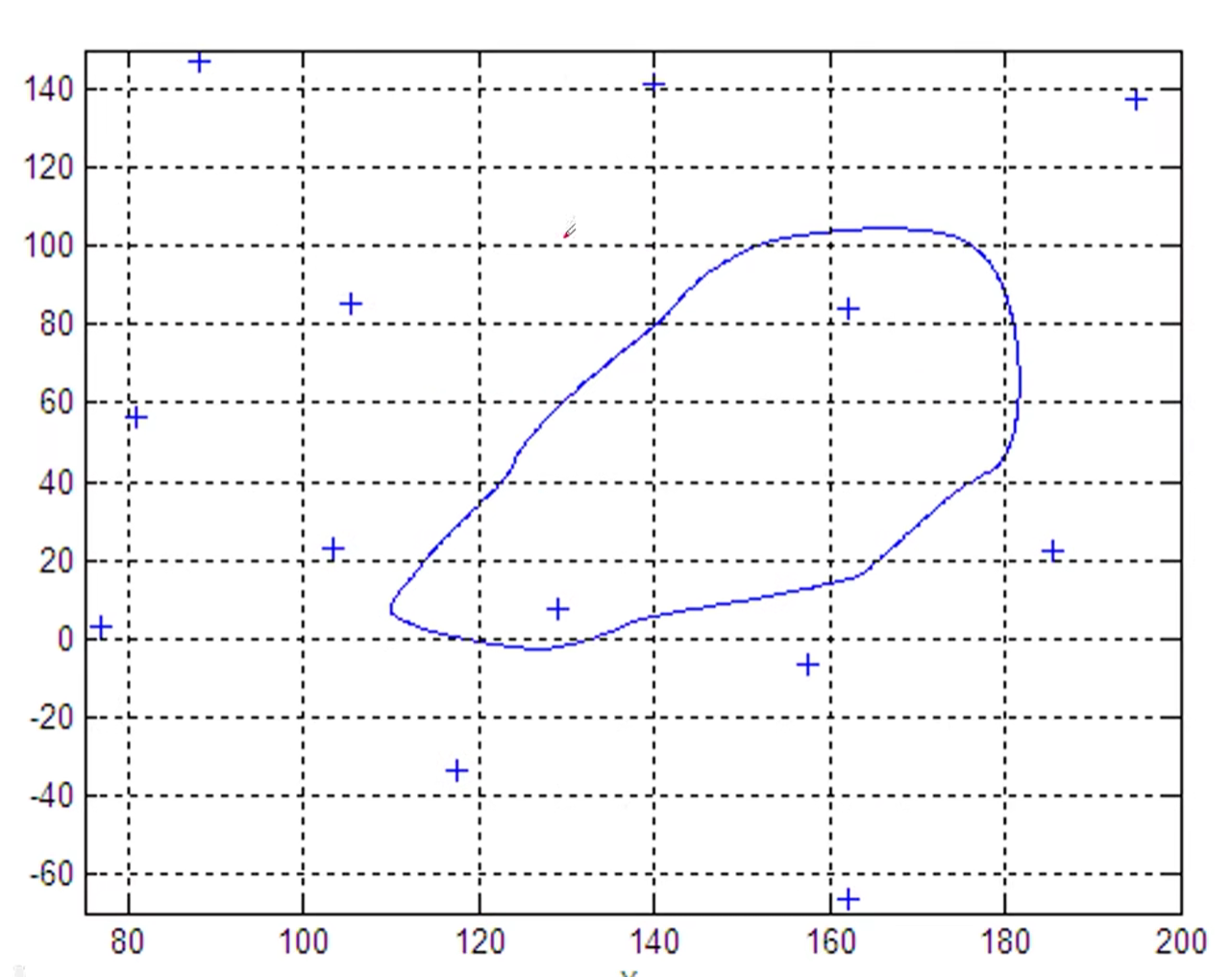
拟合问题(一般为2维)
- 小样本预测
- 拟合求导
例题1.1从1点到12点每隔一个小时测量一次温度,测得的温度依次为:5,8,9,15,25,29,31,30,22,25,27
1.每隔1/10小时的温度值,并做出温度变化图形(插值法,这里就不写解答了)
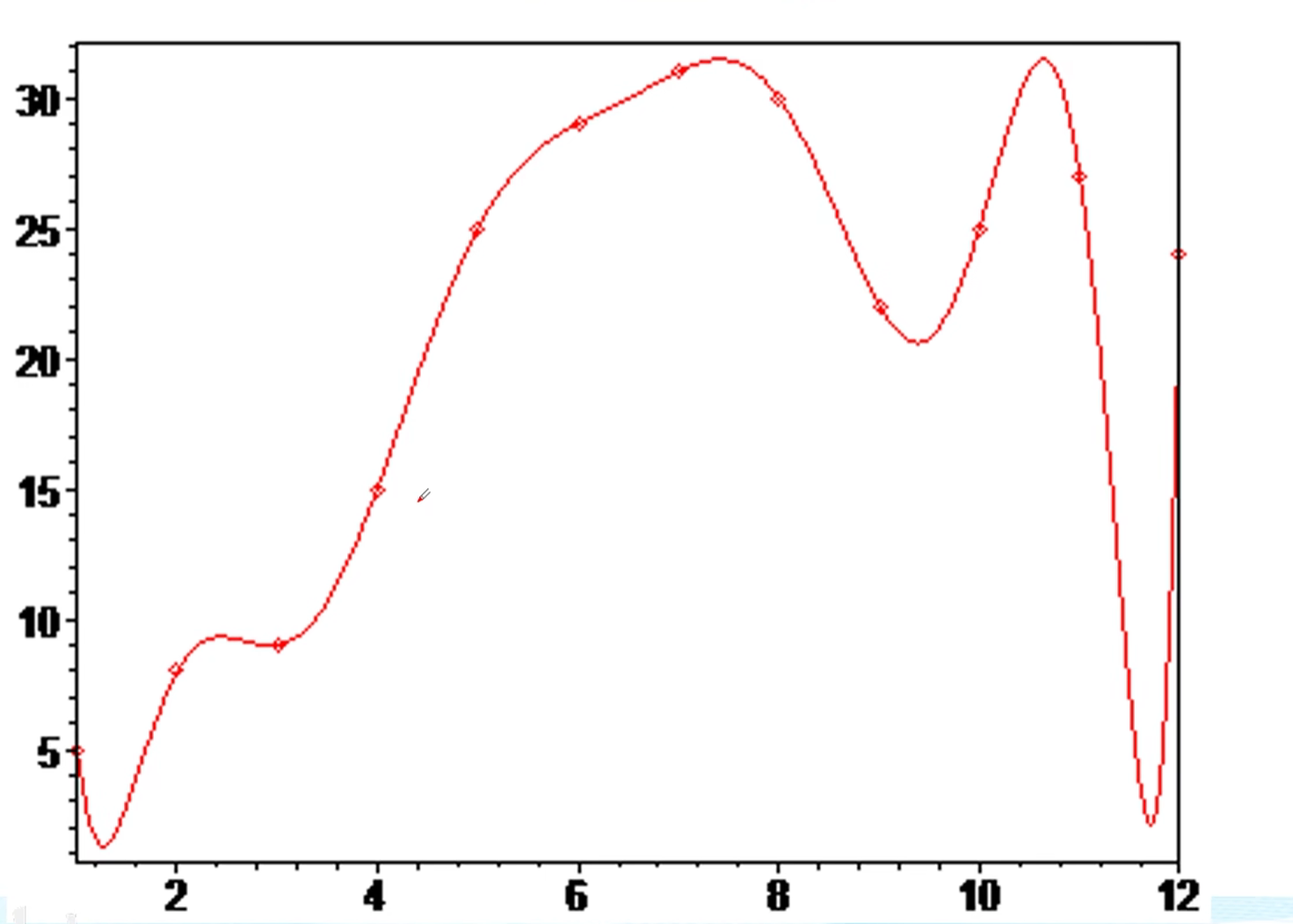
2.推测t=13.5时的温度(拟合)
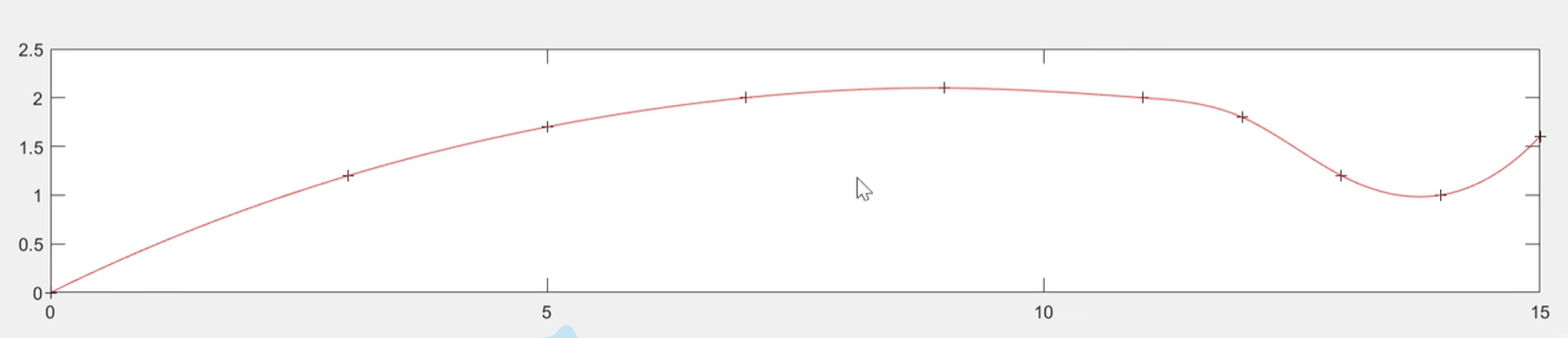
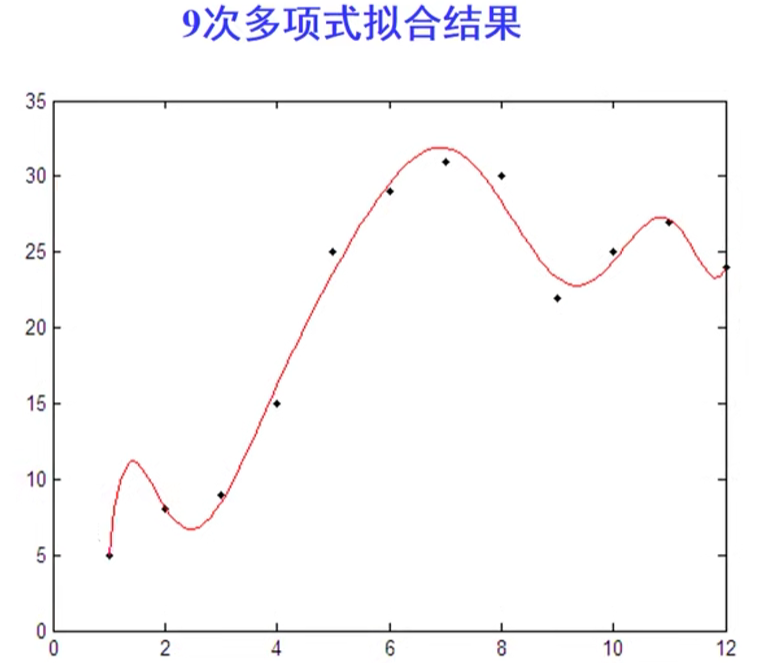
高次插值出现了Runge现象,外推t>12时的数据出现了巨大误差
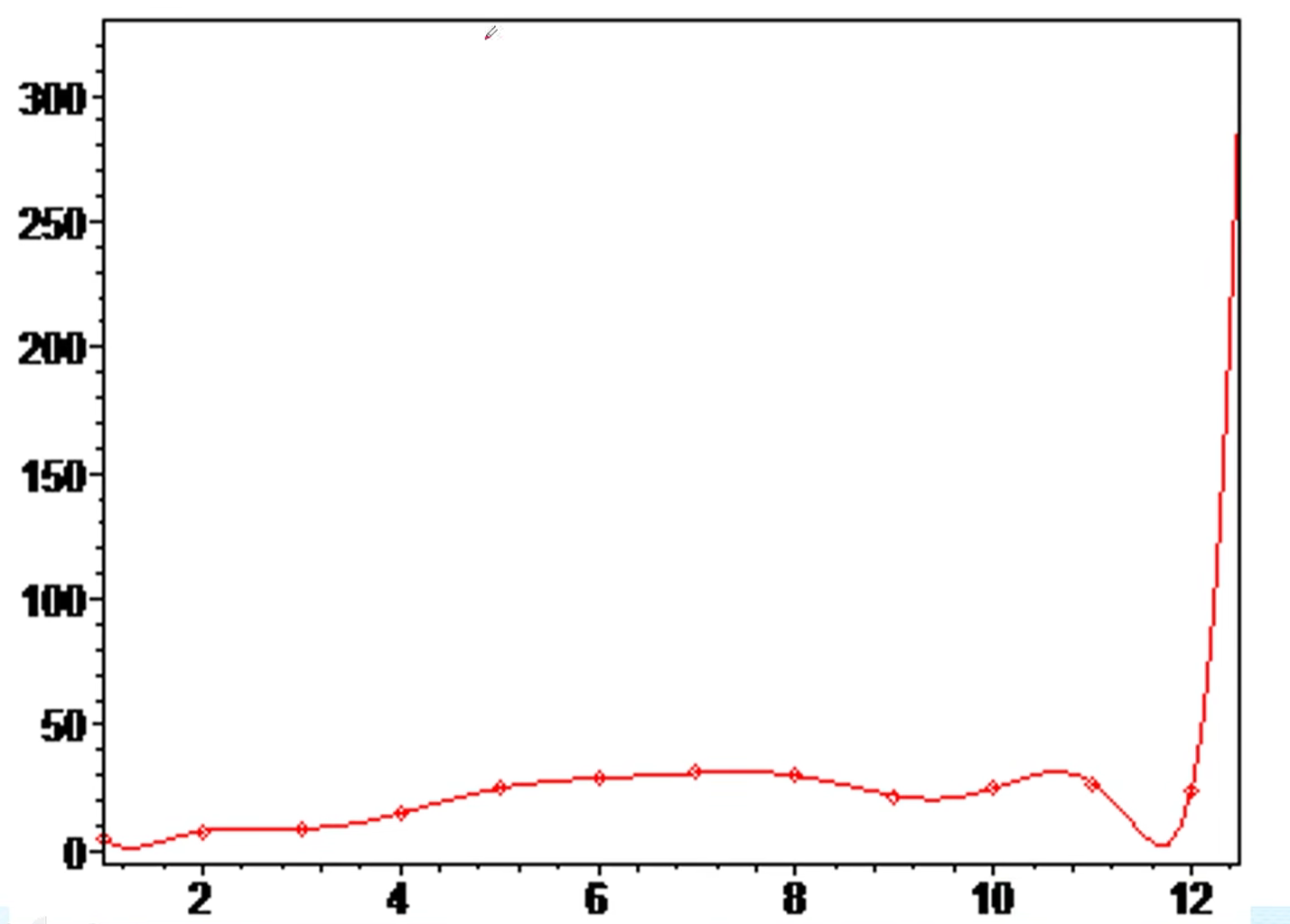
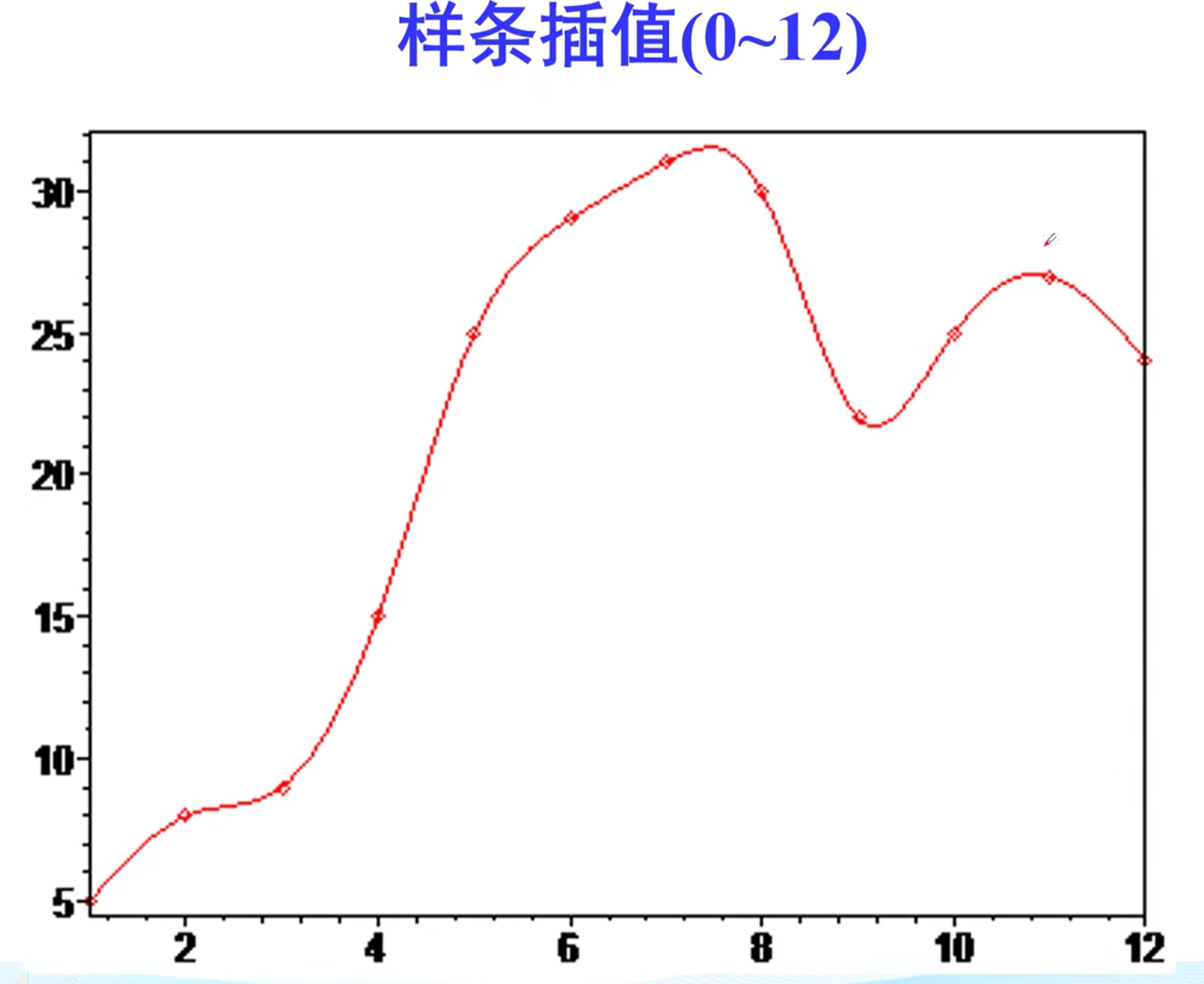
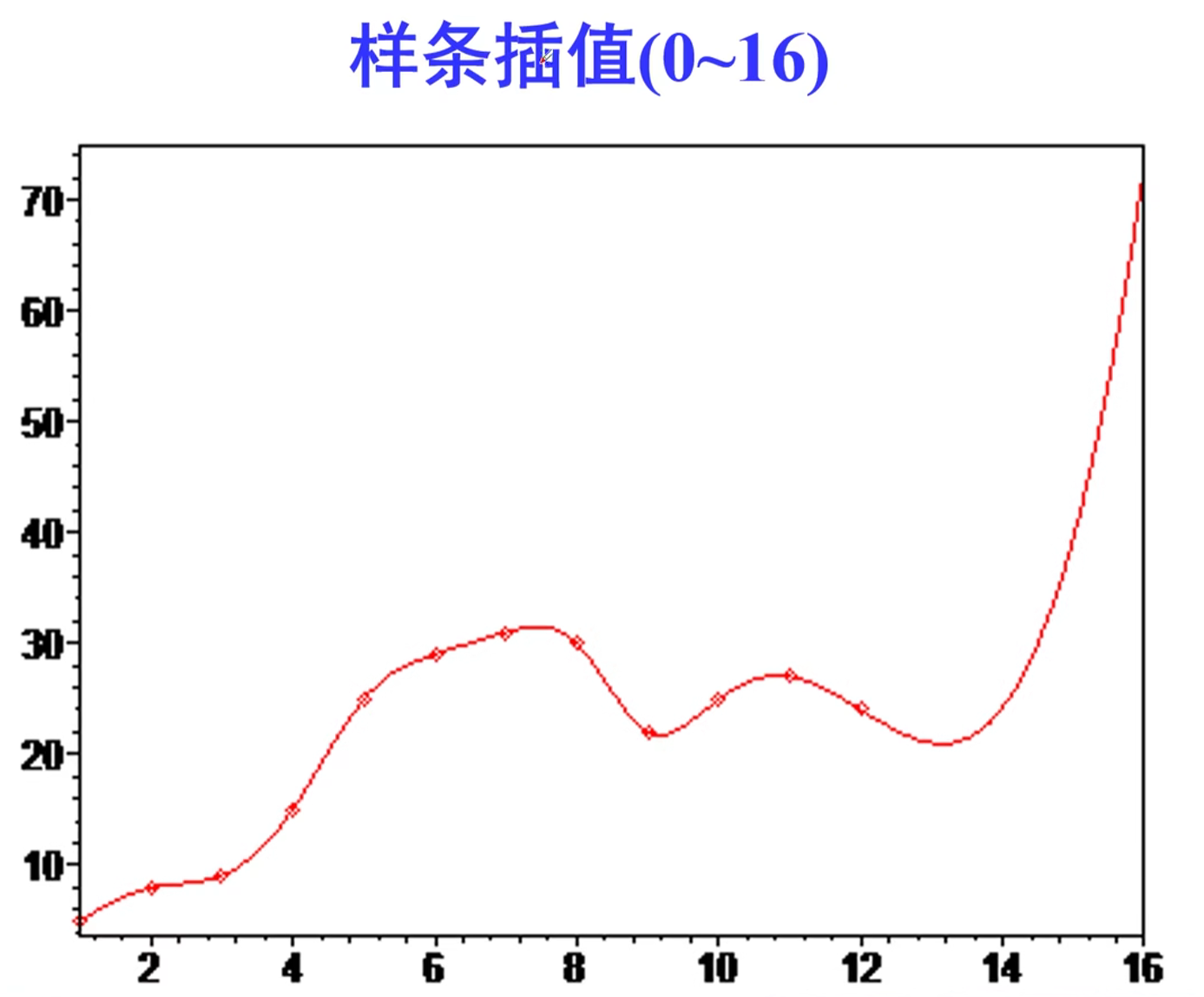
样条插值的第一个图表明样条插值可以很好地解决第一个问题,但第二个图示显示,用样条插值外推t>12时数据也会产生较大误差
拟合问题与插值问题的区别在于:
- 插值函数过已知点,而拟合函数不一定过已知点
- 插值主要用于求函数值,而拟合的主要目的是求函数关系,从而进行预测等下一步的分析
线性拟合中参数的计算可采用最小二乘法,而非线性拟合参数的计算则要用Gauss-Newton迭代法
matlab拟合(线性)
- 多项式拟合:$[a,S]=polyfit(x,y,n)$,其中x和y是被拟合数据的自变量和因变量,n为拟合多项式的系数
例如:$a_1+a_2x^2+a_3x^3+a_4x^4$中系数就是4,a为拟合多项式系数构成的向量,S为分析拟合效果所需要的指标(可省略)
1 | x=1:12; |
matlab(非线性拟合)
- 命令格式为:$[b,r]=ployfit(x,y,fun,b0,option)$x,y为已知点坐标fun指拟合函数,b0为拟合参数的初始迭代值,option为拟合选项,b为拟合参数,r为拟合残差
- 非线性函数需要提前把数据点展开
- 找近似的函数关系
- 从近似的函数关系(fun)找未知数和初值个数(x,b)
例如:$e^{-b_1x}+b_2$其中未知数就是x,初值个数为2个(b1,b2),b1和b2可以随意赋值,fun的格式就为@(x,b),@为定义一个参数,有两个参数x和b
代码1.2(其中的函数关系为:$b_1t^{\frac{-t}{b_2}}+b_3t^{\frac{-t}{b_4}}+b_5,需要提前找到函数关系$)
1 | x=1:16; |
matlab拟合可用工具:cftool

- RMSE剩余标准差误差
- SSE平方和误差
- R-square相关系数


