数学建模算法入门3
数据降维处理的算法:(评价模型)
主成分分析法(所有主成分的数量=指标数量,各主成分的累计方差贡献率>80%,或特征根>1)SPASS图像
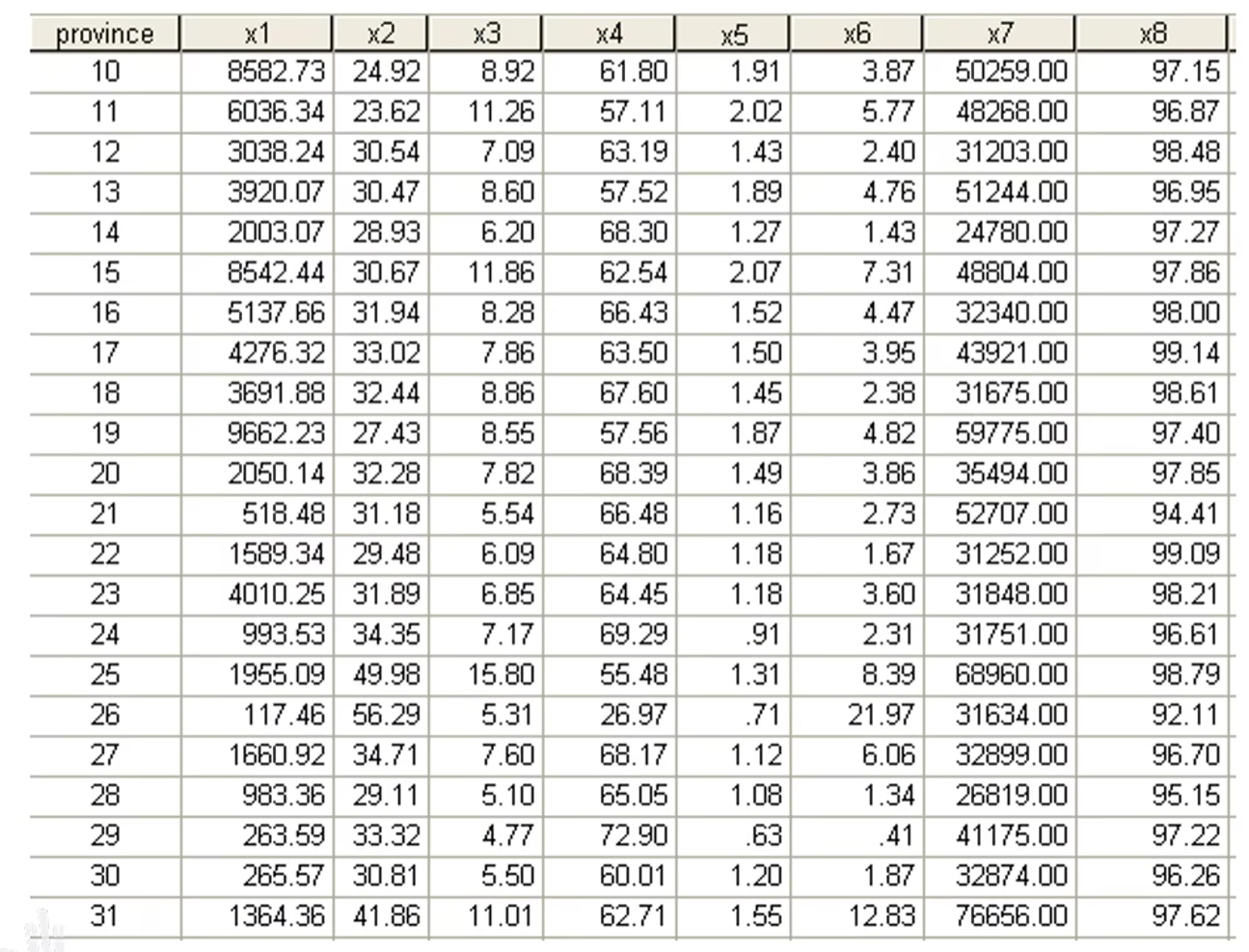
例题1.1有31个样本,每个样本有8个变量
要从原来的所有变量得到新的综合变量,一种较为简单的方法是作线性变换,使得新的综合变量为原变量的线性组合
- (var()为求方差的意思)$var(cF_1)=c^2var(f_1)$,c为常数
- 为使得方差var(Fi)可以比较$a{i1}^2+a{i2}^2+a{ip}^2=1$
- 要求原始变量有一定相关性
- 要求各个综合变量之间互不相关,即协方差为0

例题1.2根据我国31个省市自治区2006年的6项主要经济指标数据,进行主成分分析,找出主成分并进行适当的解释
| A | B | C | D | E | F | G | |
|---|---|---|---|---|---|---|---|
| 1 | 地区 | 人均GDP(元) | 财政收入(万元) | 固定资产投资(亿元) | 年末总人口 (万人) | 居民消费水平(元/人) | 社会消费品零售总额(亿元) |
| 2 | 北京 | 50467 | 11171514 | 3296.4 | 1581 | 16770 | 3275.2 |
| 3 | 天津 | 41163 | 4170479 | 1820.5 | 1075 | 10564 | 1356.8 |
| 4 | 河北 | 16962 | 6205340 | 5470.2 | 6898 | 4945 | 3397.4 |
| 5 | 山西 | 14132 | 5833752 | 2255.7 | 3375 | 4843 | 1613.4 |
| 6 | 内蒙古 | 20053 | 3433774 | 3363.2 | 2397 | 5800 | 1595.3 |
| 7 | 辽宁 | 21788 | 8176718 | 5689.6 | 4217 | 6929 | 3434.6 |
指标标准化:分析->描述统计->描述->导入数据->将标准化值另存为变量->结果
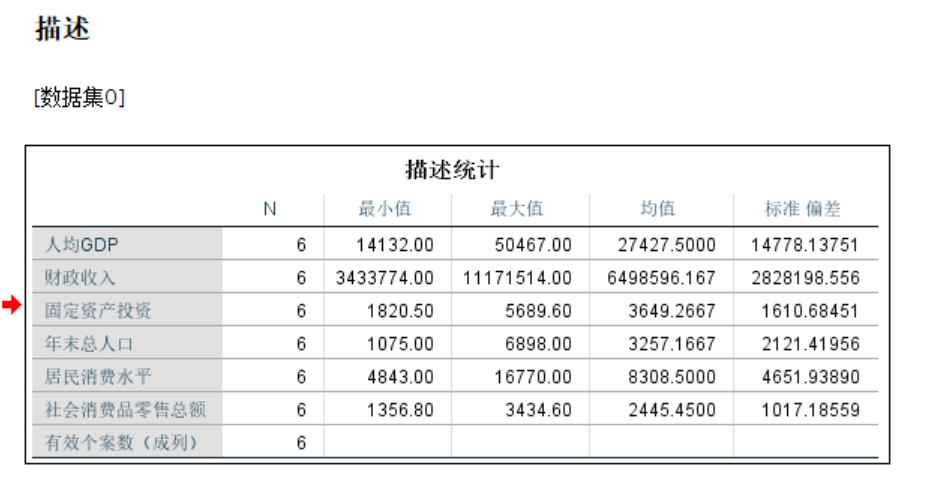
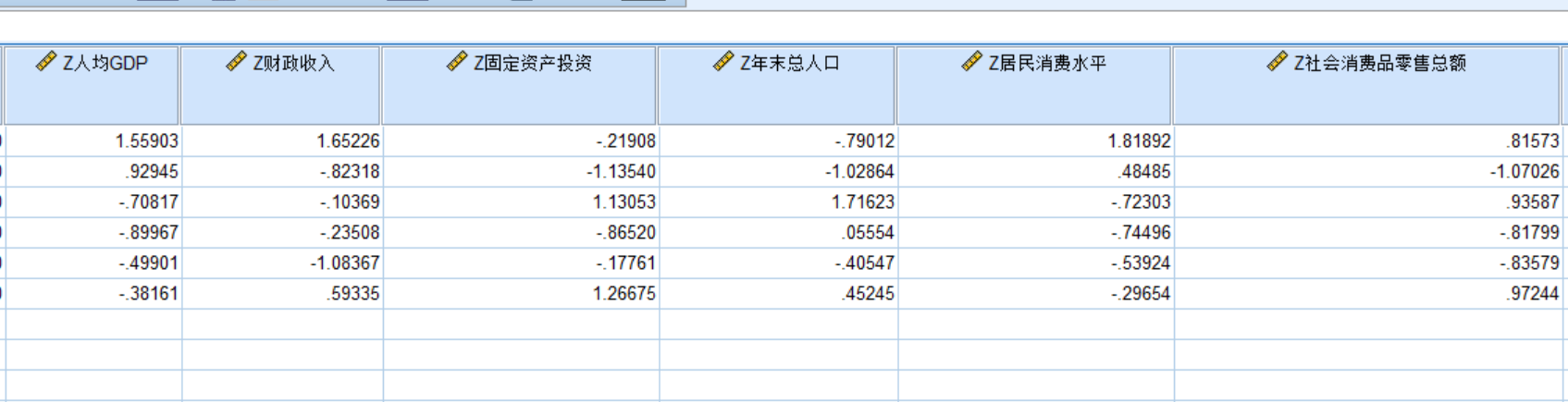
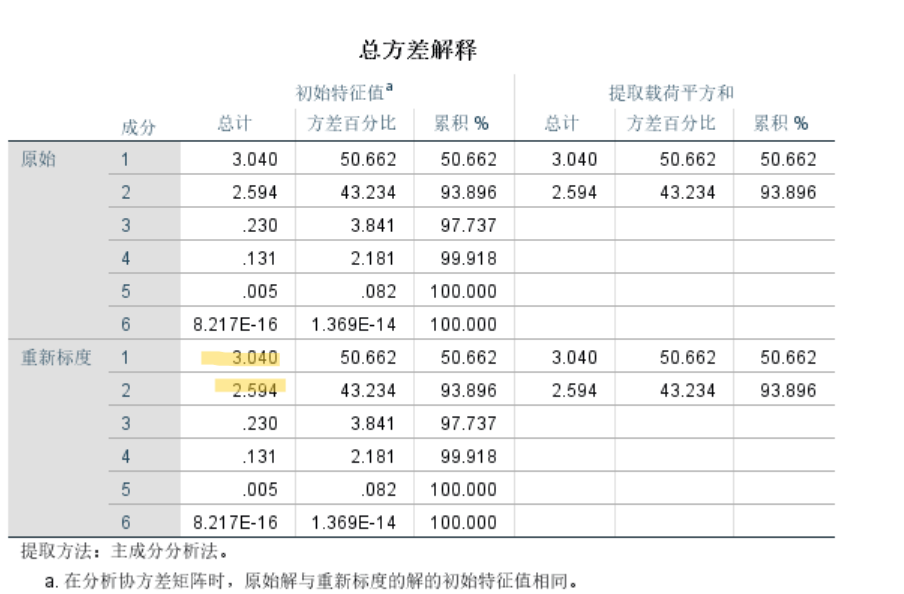
进行主成分分析:分析->降维->因子->把标准化处理过的导入->描述->初始解->KMO和巴特利特球形度检验->得分->保存为变量->回归->显示因子得分系数矩阵
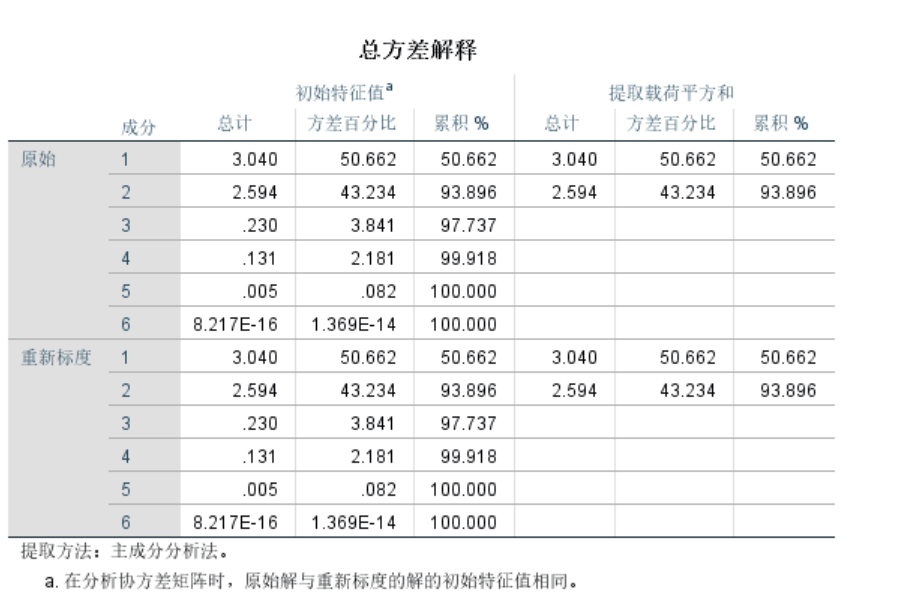
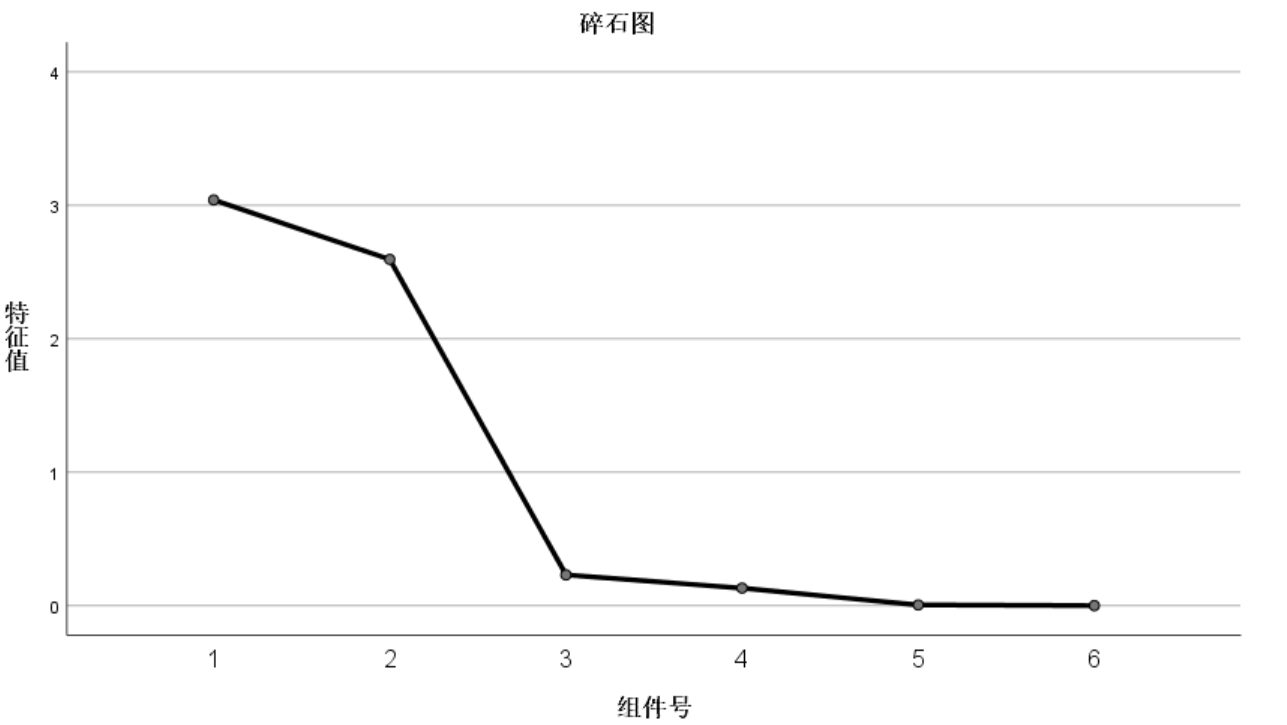
上图显示的是特征值,如果特征值累计值超过百分之85,例如如图的前两个已经到了百分之85,则选1,2作为主成分
此时成分矩阵(下图)并不是主成分分析的系数,而是因子分析
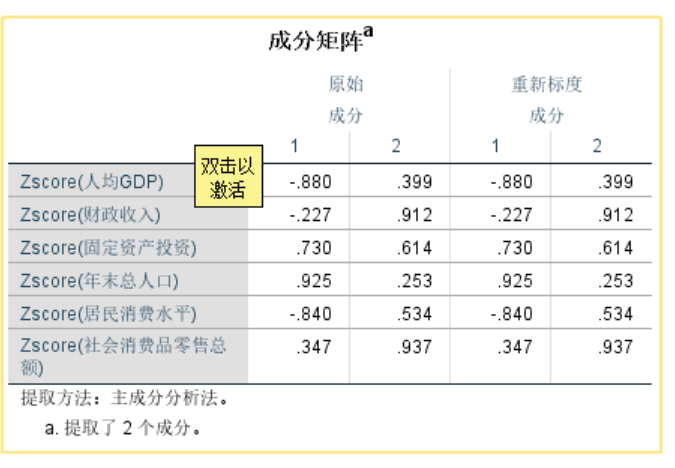
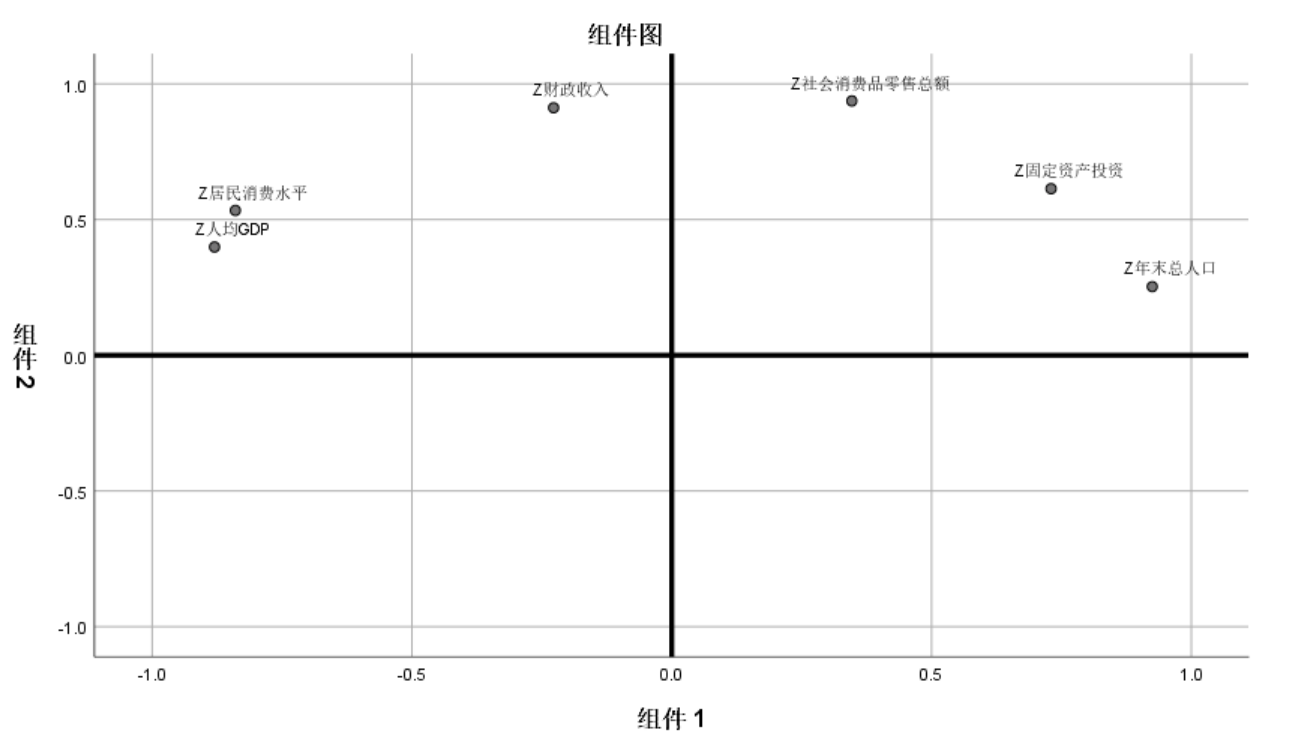
重新标度后成分取值在1~-1,其中第一个主成分代表的是人均GDP,固定资产投资,年末总人口,居民消费水平,第二个主成分代表的是财政收入,固定资产投资,社会消费品零售总额 (也可以用分析->降维->因子分析->旋转->载荷图,或者提取->碎石图看出来)
因子分析和主成分分析之间的切换:因为已经得出成分矩阵了,只需要除以$\lambda$得到新的特征向量
转换->计算变量->(目标变量随意起名字)$V1/\sqrt{\lambda},其中\lambda=总方差解释中的重新标度的值$
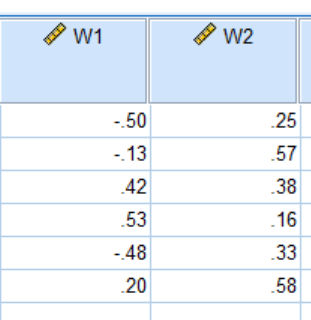
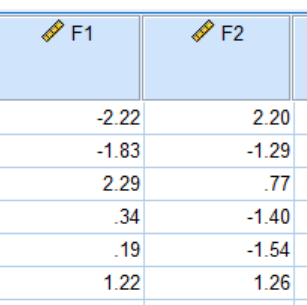
计算最终答案:
模糊综合评价模型(适用于少量数据支撑情况下的评价问题)
模糊集:长,短;多,少;高,矮 这类现象不满足”非此即彼”的排中律,而具有“亦此亦彼”的模糊性:
设给定论域U,所谓U上的一个模糊集A是指对于任意$x∈U$,都能确定一个正数$\mu_A(x)∈[0,1]$用其表示x属于A的程度,映射$x∈U->\mu_A(x)∈[0,1]$称为A的隶属函数,函数值$\mu_A(x)$称为x对A的隶属度,每个元素都有隶属度的集合称之为模糊集
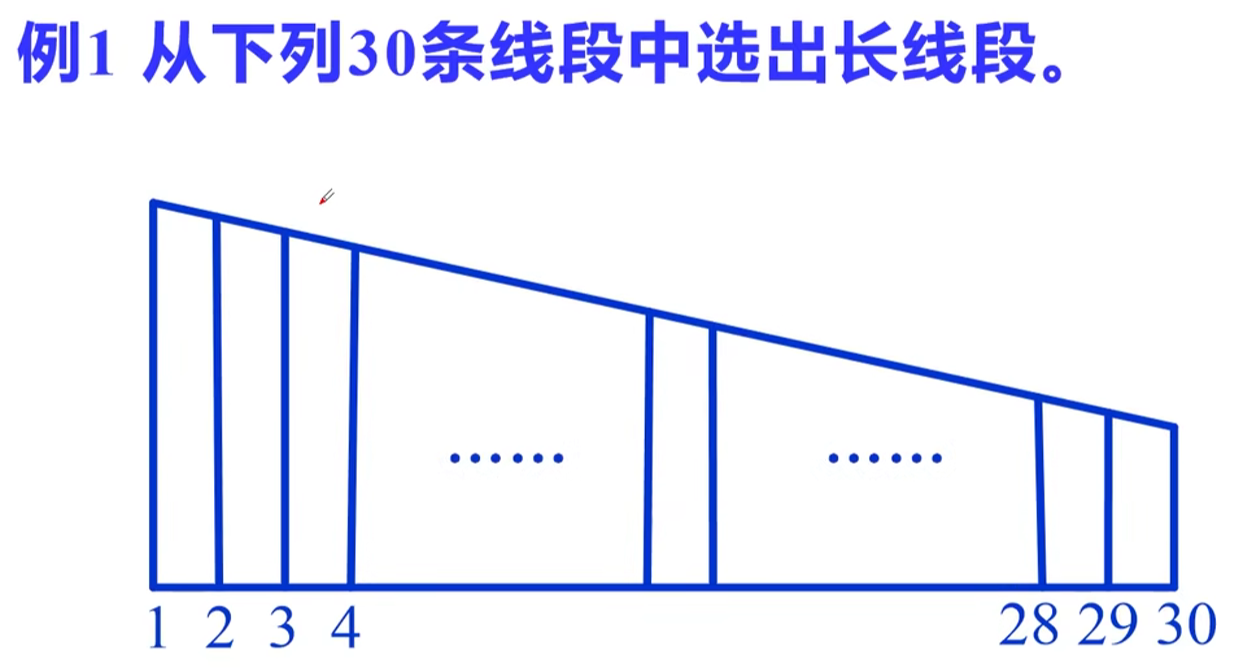
设$x_i$表示第i(i=1,2,…,30)条线段,则论域$U=\left { \begin{array}{lr**}
x1,x_2,…,x{30}\end{array} \right }$若A为“长线段”的集合,则线段$xi$作为集A的成员资格,就是$x_i$对A的隶属度。因为线段越长,属于A的程度越大,所以线段的长短可以作为A的隶属度,从而令$A(x_1)=1,A(x{30})=0$,作直线$A(x_i)-0=\frac{1-0}{1-30}(i-30),A(x_i)=\frac{1}{29}(30-i),i=1,2,…,30$
隶属函数的分类:
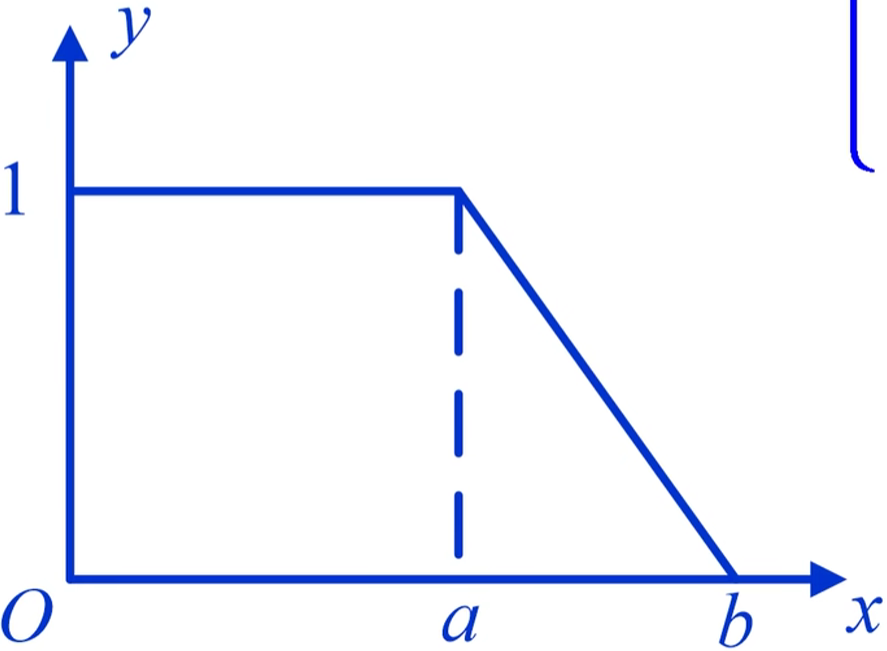
偏小型:$A(x)=\left { \begin{array}{lr**}1,x
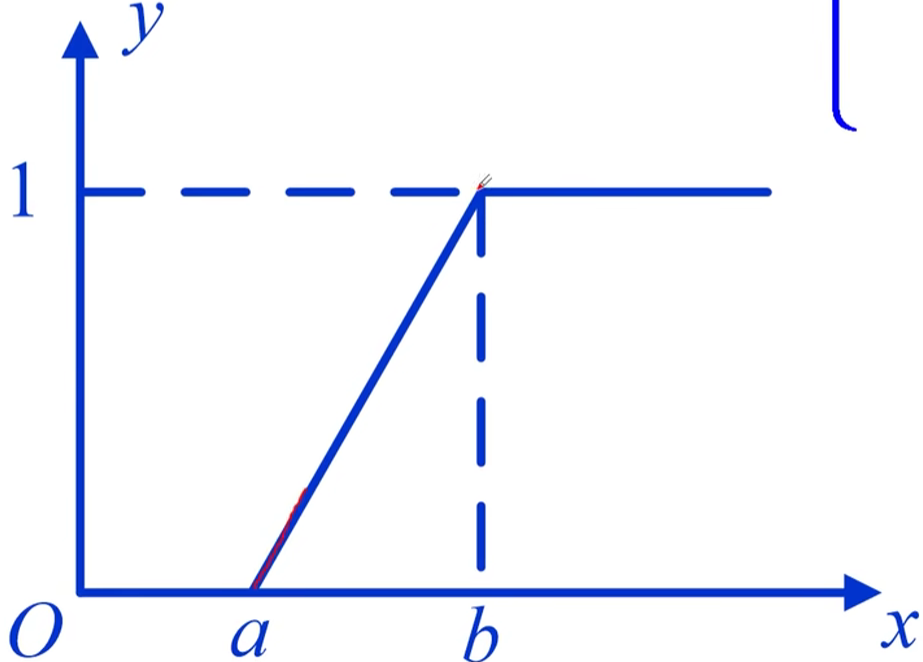
偏大型:$A(x)=\left { \begin{array}{lr**}1,x中间型:$A(x)=\left { \begin{array}{lr**}0,x
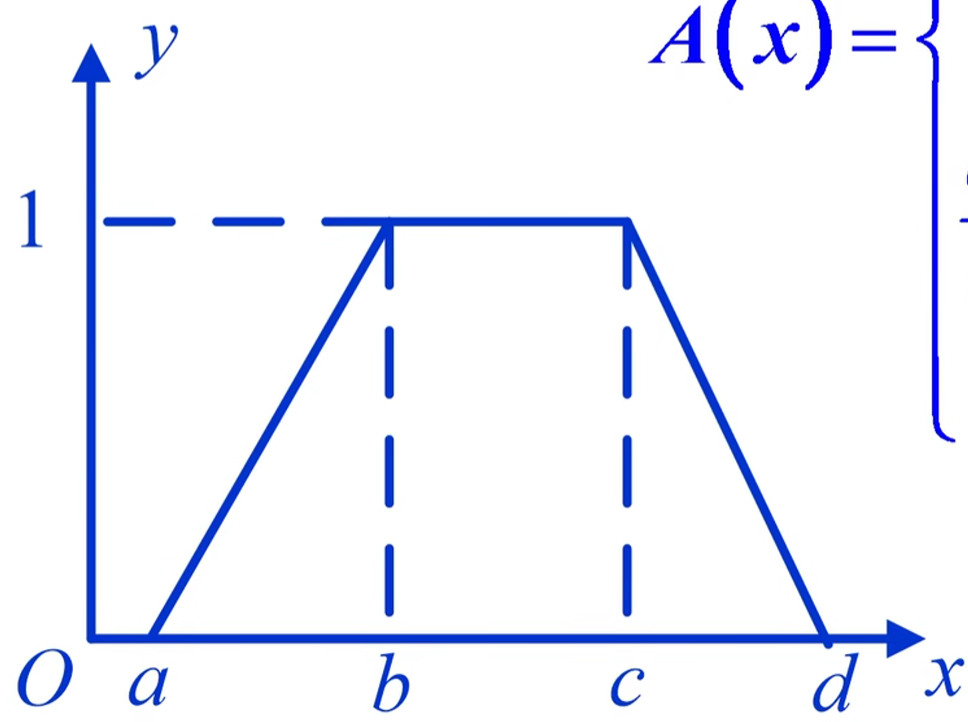
模糊评价:
例题1.1 某服装厂采用模糊综合评价法来了解顾客对某种服装的欢迎程度。顾客是否喜欢某种服装,与话说,样式,价格,耐用度和舒适度有关,故确定评价服装的因素集为U={花色,样式,价格,耐用度,舒适度}
1.由市场调研得出分别对各个因素的受欢迎程度为(评价指标)
R1={0.2,0.5,0.3,0},R2={0.1,0.3,0.5,0.1},R3={0,0.1,0.6,0.3},R4={0,0.4,0.5,0.1},R5={0.5,0.3,0.2,0}得出模糊综合评价矩阵为$A=\left { \begin{array}{lr**} 0.2\quad0.5\quad0.3\quad0\0.1\quad0.2\quad0.5\quad0.1\ 0\quad0.1\quad0.6\quad0.3\0\quad0.4\quad0.5\quad0.1\ 0.5\quad0.3\quad0.2\quad0\\end{array} \right.$
2.评价指标权重的确定(花色,耐用度,…谁更重要),确定权重通常有主观和客观两类方法,主观法的代表是层次分析法,客观法是根据各指标的联系,利用数学方法计算出各指标的权重,如质量分数法,变异系数法
通常引入一个模糊向量$A=(a_1,a_2,…,a_n)$来表示各评价指标在目标中所占权重,称为权重向量
变异系数法:已知5个投资方案如下表,试确定4个评价指标的权重
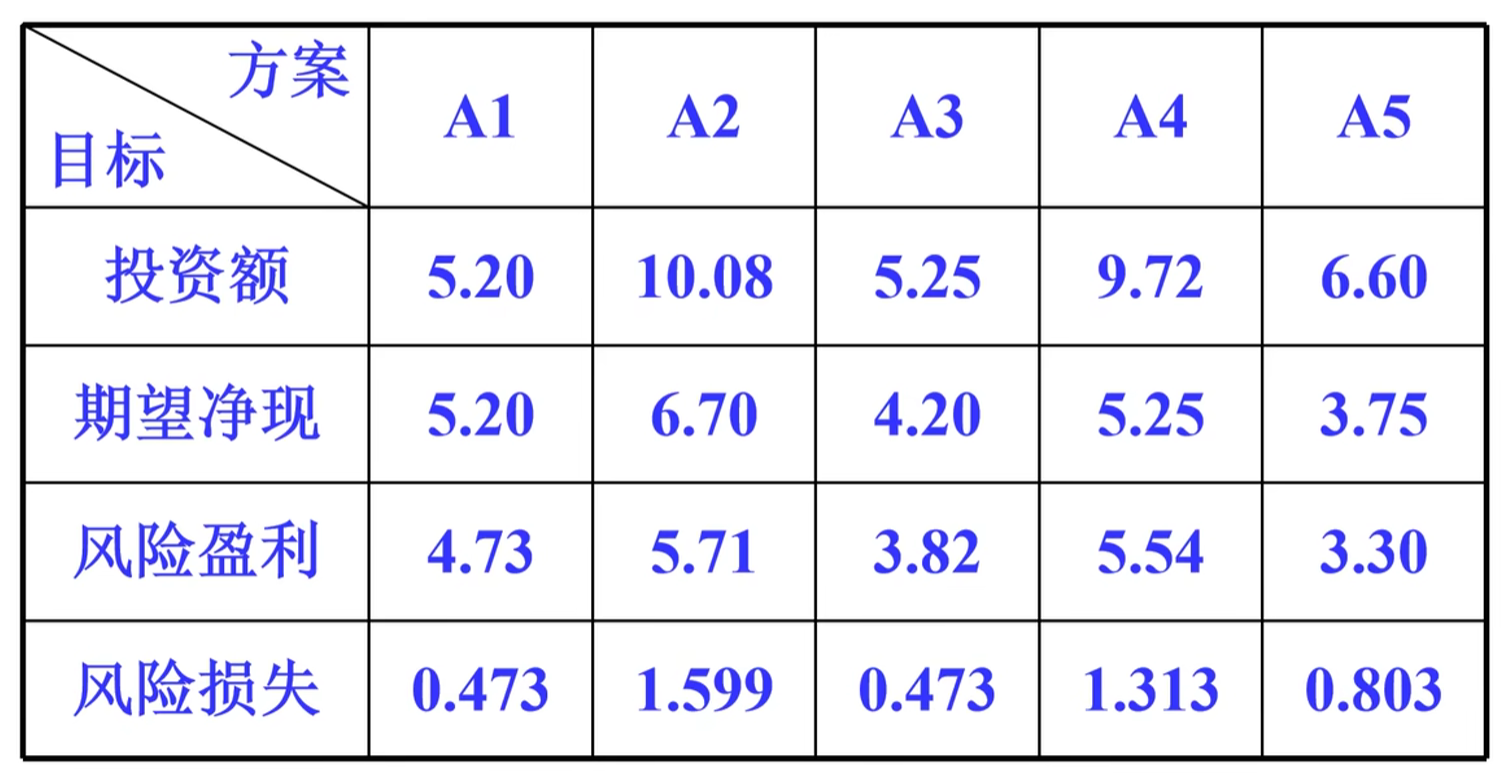
变异系数法的设计原理:将波动幅度高的指标,给与较大的权重,因为方差可以描述取值的离散程度,即某指标的方差反映了该指标的分辨能力,所以可以用方差定义指标的权重
- 计算第i项指标的均值与方差$\overline{Ai}=\frac{1}{n}\sum{j=1}^{n}a{ij},s_i^2=\frac{1}{n-1}\sum{j=1}^{n}(a{ij}-\overline{x_i})^2$令$v_i=s_i/|\overline{x_i}|$,则归一化的$v_i$ (如果此时v的值都在0~1范围内就不需要归一化,否则要对原始数据进行归一化处理) 即为各指标的权重,$归一化方法:\frac{v_i-v{imin}}{v{imax}-v{imin}}$即$\omega_i=v_i/\sum{v_i}$
结果:$\overline{x_i}=7.37,s_i=2,38,v_1=s_1/\overline{x_1}=2.38/7.37=0.323,同理v_2=0.227,v_3=0.228,v_4=0.544$从而$\omega_1=0.244,\omega_2=0.172,\omega_3=0.172,\omega_4=0.412$ 其实只能判断哪些指标分辨率更强,但不是谁最重要
3.模糊合成与综合评价
其实也可以取M为普通的矩阵乘法,此时合成即为加权平均(效果不好),至于到底取何种算子取决于问题的性质和算子的特点
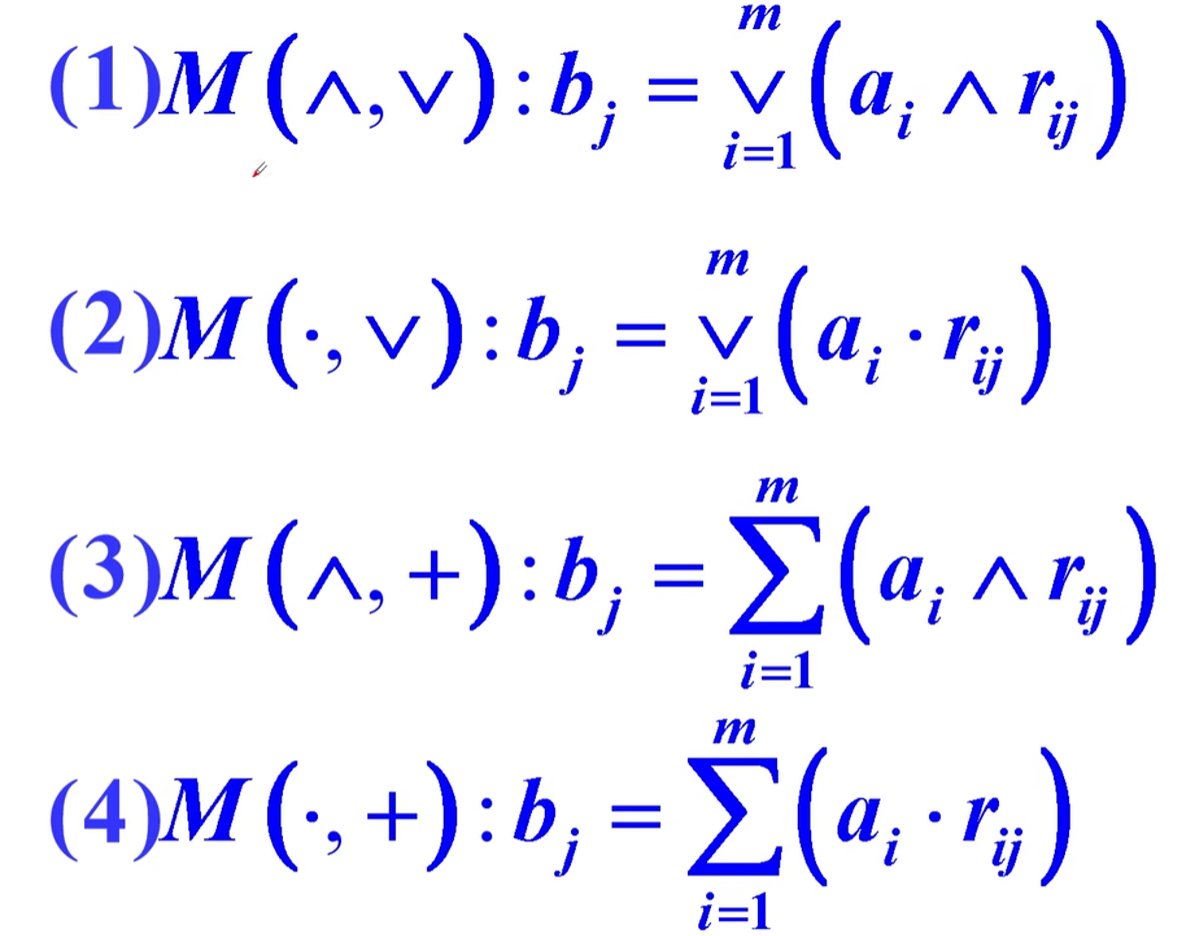
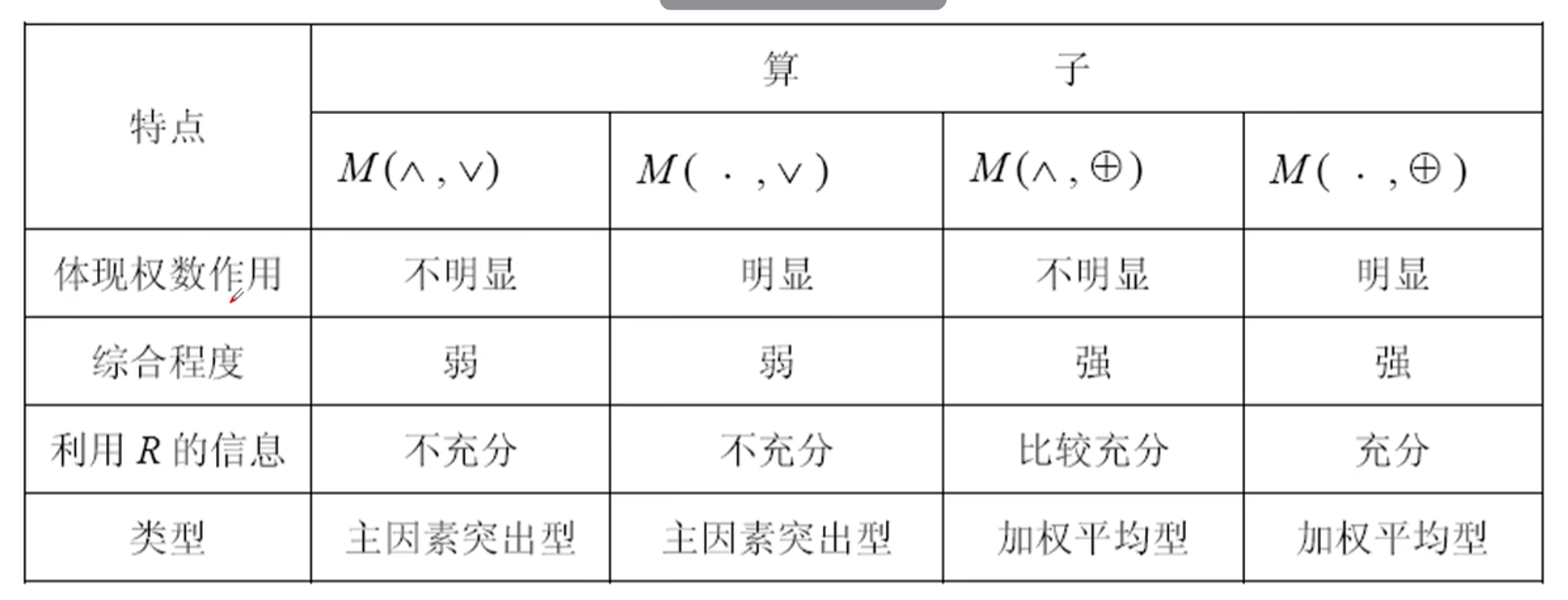
乘法体现权数作用,取和的时候综合程度强,相乘就是利用R的信息(图上有误)
主因素突出型适用于模糊矩阵中数据相差很悬殊的情形,而加权平均型则常用于因素很多的情形,可以避免信息丢失
例题1.3.1在教学过程的综合评价中,取U={清楚易懂,教材熟悉,生动有趣,板书整齐},V={很好,较好,一般,不好}。设某班同学对教师的教学评价矩阵为$R=\left[\matrix{0.4 & 0.5 & 0.1 & 0\0.6 & 0.3 & 0.1 & 0\0.1 & 0.2 & 0.6 & 0.1\0.1 & 0.2& 0.5 & 0.2}\right]$,若考虑权重A=(0.5,0.2,0.2,0.1)试求学生对这位教师的综合评价
利用A和R,利用四种合成算子编程计算得$B=\left[\matrix{0.3333 & 0.4164 & 0.1667 & 0.0833\0.3200 & 0.4000 & 0.2000 & 0.0800\0.3390 & 0.4237 & 0.2033 & 0.0339\0.3500 & 0.3700& 0.2400 & 0.0400}\right]$
过程如下:
1.权重A的每一行元素和R分别和每一列元素相比得到最小$(0.4,0.2,0.1,0.1);(0.5,0.2,0.1,0.1);(0.1,0.1,0.2,0.5);(0,0,0.1,0.1)$
2.再将得出的每一括号内的元素取最大值为$0.4,0.5,0.2,0.1$
3.因为所有$b_i$相加应该等于1,0.4,0.5,0.2,0.1都在0~1范围内,已经归一化了,但是相加得0.4+0.5+0.2+0.1=1.2不为1,就用0.4除以他们的综合,其他同理,结果为以上
注意:这道题简单于,给出了权向量A和评价矩阵R,一般情况下不会给,要根据变异方差法求A,求R的常用方法有相对偏差法和相对优属度法,在数学建模中还可以考虑与灰色系数分析连用
相对偏差法
1.4.1例题先有下列5个农业奇数经济方案,试评价各方案的优劣
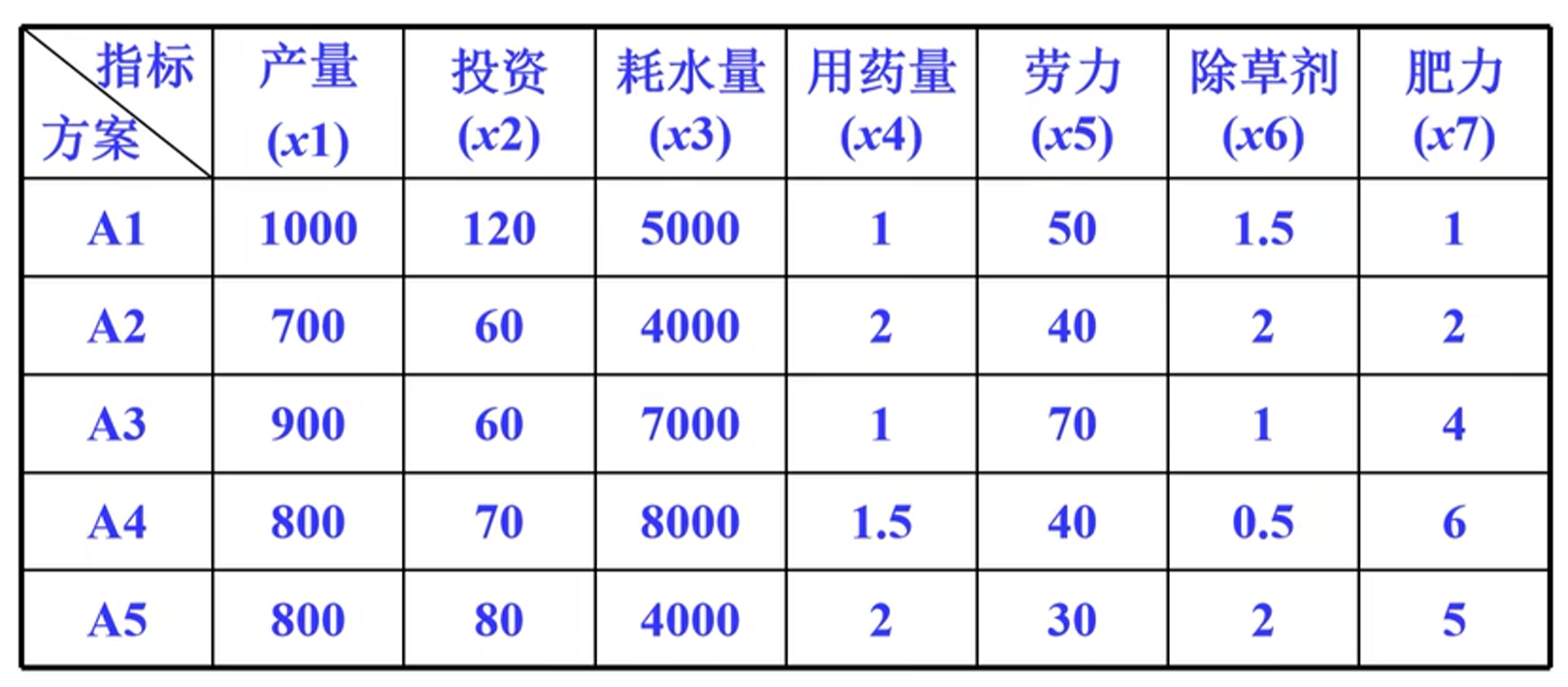
1.产量和肥力为效益性指标,其他为理想型指标,效益性指标用最大值,理想型指标用最小值:u={1000,60,4000,1,30,0.5,1}
2.根据前述方法求出相对偏差模糊矩阵:$\frac{最大值-该值}{最大值-最小值}=\frac{1000-1000}{1000-700}=0$
$R=\left[\matrix{0 & 1 & 0.25 & 0 & 0.5 & 0.66 &1\1 & 0 & 0 & 1&0.75&1&0.8\0.333 & 0 & 0.75 & 0&0&0.33&0.4\0.667 & 0.17& 1 & 0.5&0.75&0&0\0.677&0.33&0&1&1&1&0.2}\right]$
3.用变异系数法求出指标权重:

$\omega=0.110,0.214,0.176,0.156,0.098,0.113,0.134$
4.各个方案加权平均值F为$\omega*R$:0.3525,0.4558,0.4505,0.5206,0.5864
5.越小越好则方案的优劣次序为:1,3,2,4,5
1 | A=[1000 120 5000 1 50 1.5 1 |
相对优属度评价法
例题1.5.1对下表中5个方案进行综合评价
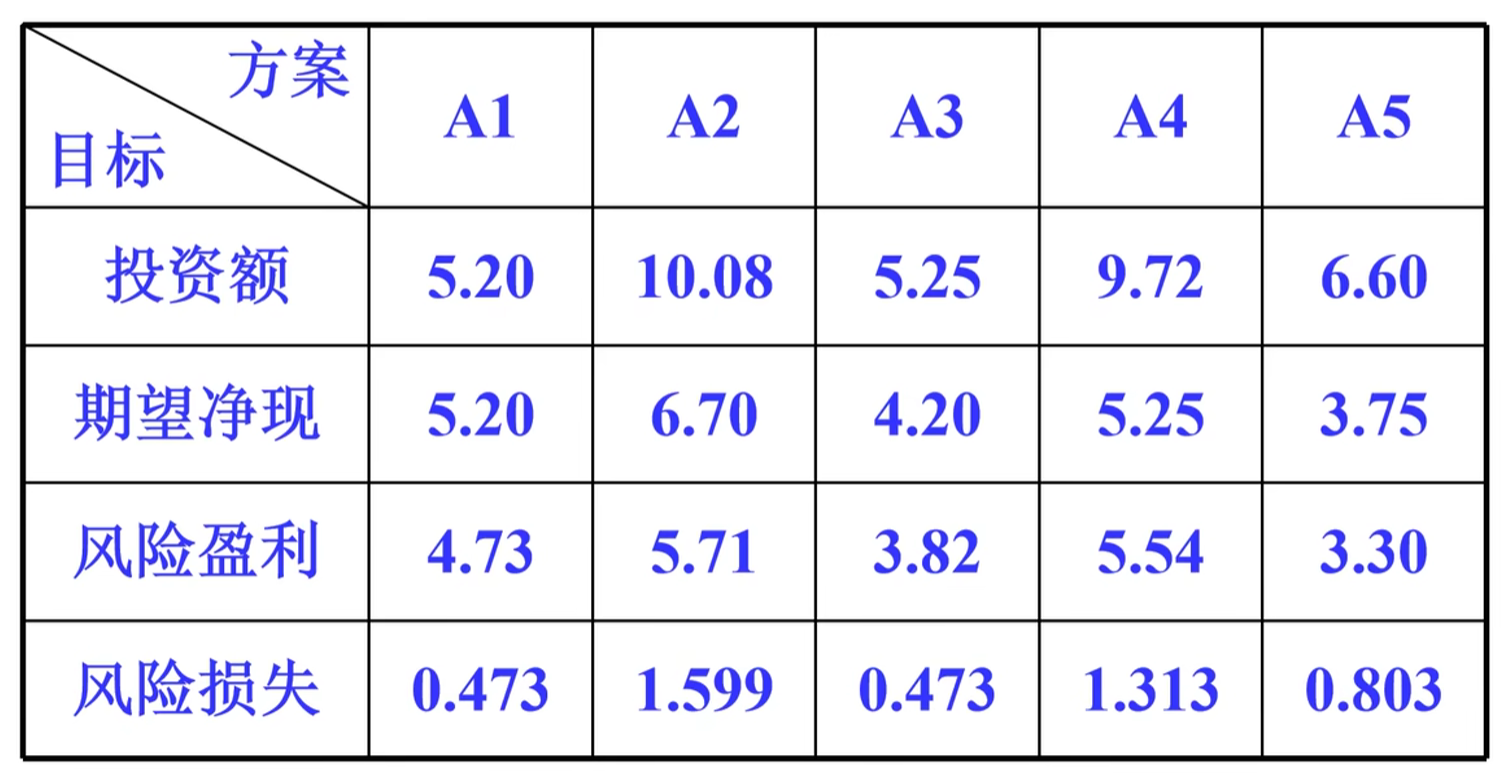
1.建立模糊效益矩阵,投资额,风险损失为成本型;期望净现值,风险盈利值为效益型
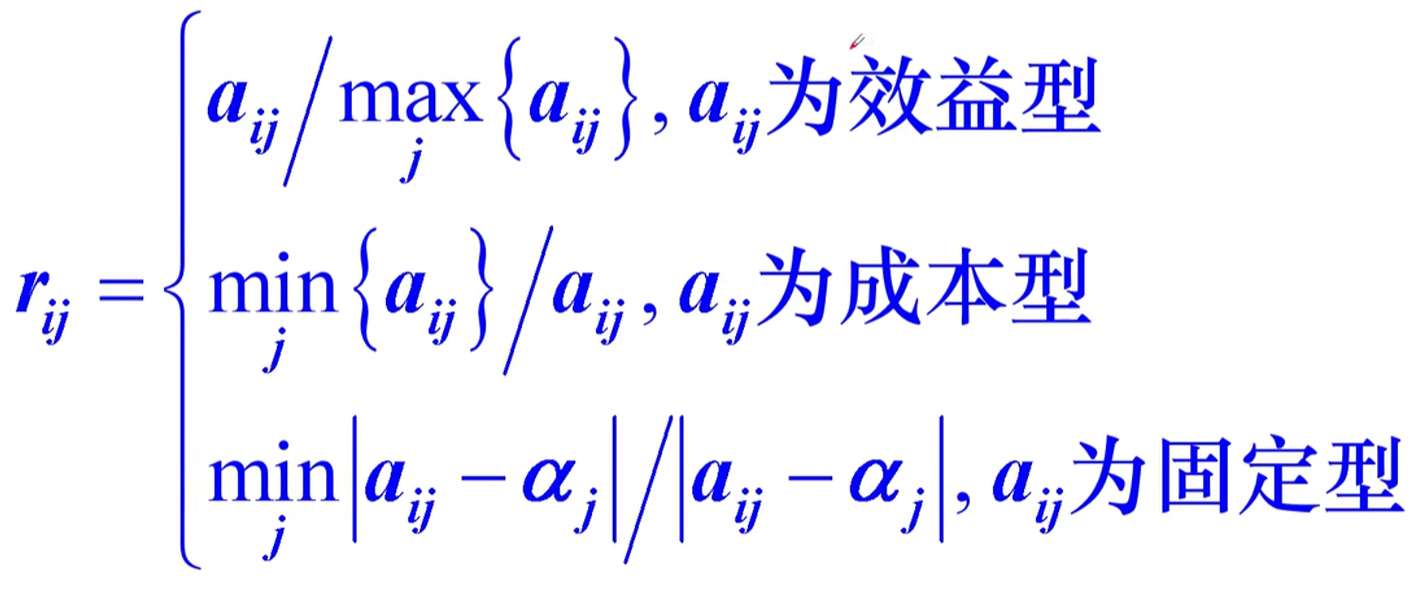
$W=\left[\matrix{1 & 0.5159 & 0.9905 & 0.5350 & 0.7879\0.7761 & 1 & 0.6269&0.7836&0.5597\0.8284 & 1 & 0.6690 & 0.9702&0.5779\1 & 0.2958& 1 & 0.3602&0.5890}\right]$


